Kubernetes Scheduler机制概览
简介
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的节点(Node)。
而这里“最合适”的含义,包括两层:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
- 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
以上文字来自于极客时间,张磊老师的《深入剖析Kubernetes》课程中的《十字路口上的Kubernetes默认调度器》这一章节,我觉得总结的相当到位,对我这个万事开头难来说,实在难以写出比这更精辟的开头了,就直接拿来主义了:-)
不过最近两年Scheduler做了不少的改进,尤其是为了让其有更好的扩展性,以及更好的维护,而重构的称之为Scheduling Framework的调度框架,已经淡化了以前Predicate & Priority的概念,还有webhook方式的扩展机制Scheduler Extender,取而代之的是Plugins以及Extension Points,即通过在各个预定义的扩展点,插入Plugin的方式,扩展Scheduler的功能,核心的调度算法逻辑,也都放到了Plugin中,如果默认的调度器中的Plugin不能满足需求,可以自己写插件,但是要重新编译代码。
此外,还有两个重量级组件,就是优先级队列和缓存(PriorityQueue and Cache),优先级队列保障Pod的调度顺序,结合上面的插件机制,用户是可以自定义优先级算法的,而缓存则主要是为了优化调度的性能而引入的,它缓存的主要是Pod和Node的信息,调度器的性能优化,也经历了一个很漫长的进化过程。
Scheduler架构
好了,下面来看下Kubernetes Scheduler在我脑海中的画像:
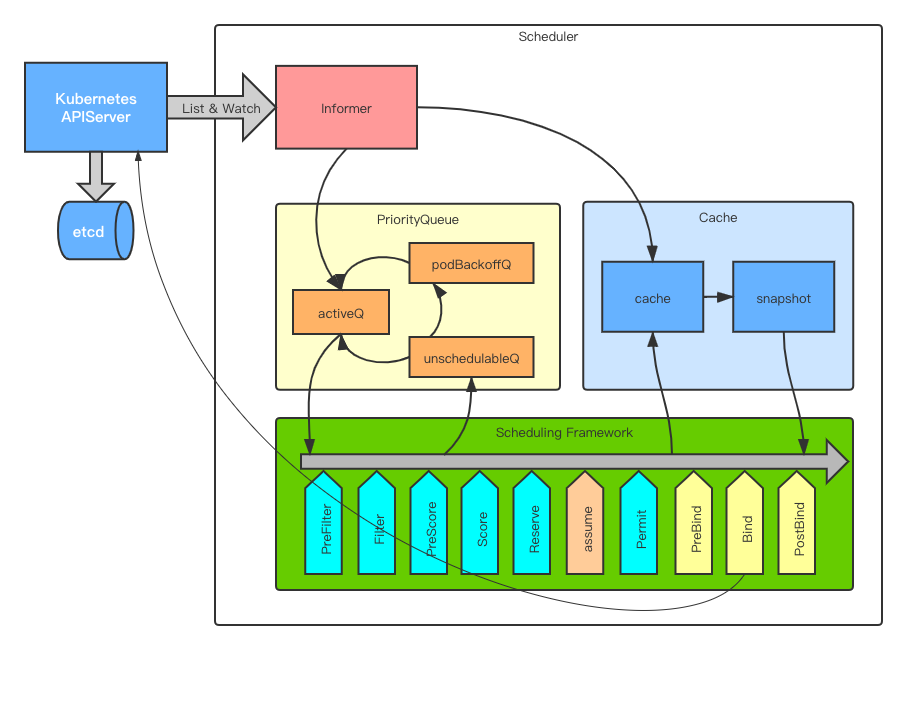
Informer
首先就是Informer了,关于Informer这里就不做过多介绍了,可以看下这篇文章《Kubernetes Informer机制解析》,介绍的比较详细。Scheduler中的Informer是一切事件的来源,它监听了很多对象的状态,但是其中主要是Pod和Node,Pod的事件又分为两种:
- 当没有调度成功的pod发生增删改事件时,该pod就会被放入到优先级调度队列中。
- 当已经调度成功的pod发生增删改事件时,该pod就会被对应的更新到缓存中。
而当有Node的增删改事件时,会将其信息更新到缓存中,以提高调度的速度。
所以,一句话总结这里的过程:未被调度的pod放到了优先级调度队列中,而已经调度的pod和node,则更新至缓存中。
PriorityQueue
这里所谓的PriorityQueue其实是由三个队列组成的:
- activeQ: 用来存放将要进行调度的pod,底层数据结构是用”堆”来实现的优先级队列;
- unschedulableQ: 用来存放调度失败的pod,底层数据结构是一个map;
- podBackoffQ: 用来作为activeQ和unschedulableQ之间的一个缓冲队列,也是一个用“堆”实现的优先级队列
首先是优先级的问题,Kubernetes中实现了一个Pod Priority的功能,可以给pod关联一个PriorityClass,指定一个权重值,权重越高,则该pod的优先级越高,在优先级队列中会越往前排,它就越会被优先调度。此处的队列,指的就是activeQ,它是一个用“堆”这个数据结构来实现的优先级队列,堆的排序算法,是可以通过FrameWork的插件机制来指定的,默认的排序插件就是按照pod的权重值来排序,如果没有指定权重值的话,则按照pod加入到队列中的时间戳来排序,也即退化成一个FIFO队列。
消费者从activeQ中取走一个pod进行调度,如果调度失败的话,则会将该pod放入到unschedulableQ中,而unschedulableQ中的pod又会周期性的被移到activeQ或者podBackoffQ中,等待重新被调度。
而podBackoffQ的存在,主要是为了解决优先级调度算法中存在的”无穷阻塞”或者是”饥饿”问题,即由于高优先级的pod总是被优先调度,而低优先级的pod一直得不到调度的问题。podBackoffQ也是一个优先级队列,不过它的排序算法就不是按照pod的权重值了,而是按照pod加入到unschedulableQ中的时间长短来排序的,即该pod等待被调度的时间越长,则在podBackoffQ中越排在前面,这样就防止了“无穷阻塞”的问题。Scheduler周期性的将超过了backoff时间的pod,从podBackoffQ移动到activeQ,进行再次调度。
可以看到这三个Queue互相配合,完美实现了优先级调度的功能。
Cache
Cache在这里的作用,主要是为了加速调度过程中查询pod和node等信息的速度,了解Informer机制的话,不免有个疑问,就是Informer其实已经在本地缓存了一份数据了,而这里为什么还要再添加一层缓存呢?其实在没有cache之前,确实是直接通过Informer获取的信息,但是Informer中缓存的数据相当于是原始数据,在调度过程中,还需要根据原始数据再实时计算出一些数据,比如该node上所有pod的request之和,或者是该node分配出去的端口号,这种实时计算的,就需要遍历一遍这个Node上所有的pod或者是container,这就会很耗费时间了,在规模环境比较大,pod数量比较多的场景下,这些还是很影响调度性能的。所以一种优化策略,就是再引入一层缓存,依赖informer的事件机制,提前在本地缓存好聚合之后的数据,这样在调度的时候,就不用再实时去计算了,时间复杂度也就从O(containers)变为了O(nodes)。
当然,这付出的代价,就是代码复杂度又变高了,该缓存的正确与否,直接影响了调度的准确性,后续为了保证调度时的一致性,又引入了snapshot机制,即每次调度pod时,都要给当前的缓存打一个快照,因为如果直接依赖缓存的话,它的数据可能随时会变化,尤其是在node和pod频繁变更时,因此通过打快照,调度前后都使用快照中的数据,保证了调度的一致性。
针对Cache的优化,社区经历了一个比较漫长的演进过程,这里面有一些很奇怪的数据结构,不了解背景的话,还真的难以理解,后面我们专门有一篇文章来盘点下那些年为提升调度性能而做的优化。
Scheduling Framework
这个算是Scheduler中的重头戏了,前面已经介绍过,它主要的特点是将调度的过程,定义了几个扩展点,每个扩展点都可以注册一些插件,通过插件的方式来实现具体的调度算法,Kubernetes Scheduler中默认的调度算法,都是通过插件来实现的。整个调度过程分为两部分:Scheduling Cycle和Binding Cycle。前者是为pod找最合适node的过程,后者是将该pod和node进行绑定的过程。
- Scheduling Cycle的扩展点:PreFilter, Filter, PreScore, Score, Reserve, UnReserve, Permit
- Binding Cycle的扩展点:PreBind, Bind, PostBind
Scheduling阶段中,Filter是用来过滤符合调度条件的node的;Score则是来给符合条件的node进行打分,从中选择一个最合适的node;Reserve则是为该pod保留资源的,比如volume;Permit是Scheduling阶段最后的步骤,它类似准入规则,或者延迟准入,只有符合了准入规则的pod,才会进入Bind阶段。
Binding阶段,主要就是用来将选出来的node和pod进行绑定,即调用pod的Bind接口,将该绑定关系写入到数据库中,该过程是异步进行的。
此外,还有一个assume操作,该操作不是一个扩展点,它是在Scheduling阶段,将选出来的node提前更新到缓存中,张磊老师称之为“乐观绑定”,我觉得很形象,其主要目的是为了不阻塞调度的关键路径,因为向apiserver发起绑定请求是一个比较耗时的操作,所以Bind这个操作是异步进行的,但是又不能等到Bind成功之后,才由Informer的事件去触发更新缓存,这样的话,下一次pod调度拿到的缓存信息,很有可能是本次Pod绑定之前的数据,它认为资源还没被分配出去,这就出现了资源调度的不一致性,所以通过assume机制,提前进行缓存更新,同时,发起异步Bind操作,假如后续Bind失败了,也没有关系,Scheduler会清空该pod的缓存,然后将该pod放入到unschedulableQ进行重新调度。
总结
本篇文章从整体上介绍了一下Kubernetes Scheduler的工作原理,从这4大块内容来看(Informer, PriorityQueue, Cache, Scheduling Framework),Scheduler在扩展性上、性能上都做了很多的优化工作,很多小细节考虑的很周到。在设计上,有很多值得学习的地方,翻看到早期的Scheduler代码,实现的非常简单,到现在功能这么健全,真心感觉罗马不是一天建成的,还有就是众人拾柴火焰高。
不过,从上面的设计上也可以看出,目前Scheduler的一个问题就是它只能是单点的,没法水平扩展,因为队列实现的是本地的内存队列,没有依赖外部服务,多个scheduler之间是没法共同协作的,只能通过LeaderElection机制做主备,或者是依赖deployment控制器,做单点服务管理,不过目前看scheduler的性能优化已经很不错了,单点就能支撑很大的规模,这里给出一个数据:在5000个node上调度10000个pod,每个pod的调度延迟只有6.7ms,这个性能已经能够满足绝大多数的集群规模。
附录
1 | 代码主线: |
Kubernetes Scheduler机制概览
https://hackerain.me/2020/12/19/kubernetes/kube-scheduler-overview.html