exempt"C ! Group system:unauthenticated */healthz2/livez2/readyz
DanglingFal"Found*]This FlowSchema references the PriorityLevelConfiguration object named "exempt" and it exists"
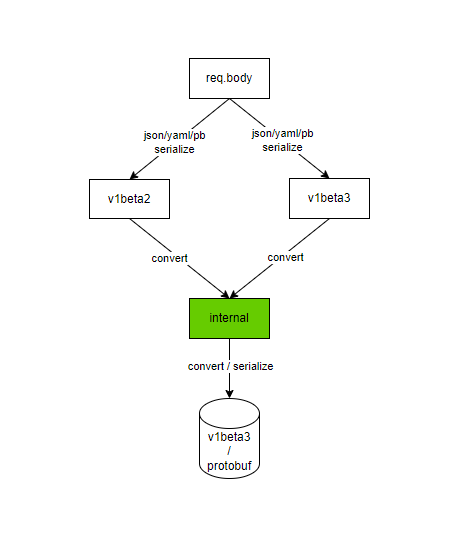
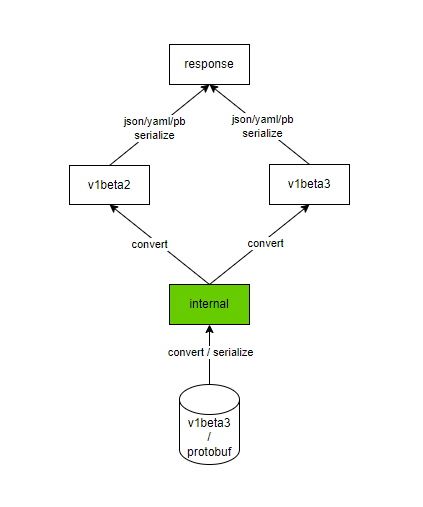
从上面的功能介绍来看,Kubernetes能够做到这个程度的API兼容,真的是很良心的,难怪它会一统江湖,Kubernetes社区将API的兼容性看得很重要,除了每个API都有一个进化迭代的过程之外,一旦API进入到GA稳定版阶段,后续对它的修改一定是不能破坏兼容性的,关于API兼容性的更多内容,可以阅读下社区的这个文档:Changing the API
type FlowSchema struct { metav1.TypeMeta `json:",inline"` // `metadata` is the standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata // +optional metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"` // `spec` is the specification of the desired behavior of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Spec FlowSchemaSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"` // `status` is the current status of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Status FlowSchemaStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"` }
// FlowSchemaSpec describes how the FlowSchema's specification looks like. type FlowSchemaSpec struct { // `priorityLevelConfiguration` should reference a PriorityLevelConfiguration in the cluster. If the reference cannot // be resolved, the FlowSchema will be ignored and marked as invalid in its status. // Required. PriorityLevelConfiguration PriorityLevelConfigurationReference `json:"priorityLevelConfiguration" protobuf:"bytes,1,opt,name=priorityLevelConfiguration"` // `matchingPrecedence` is used to choose among the FlowSchemas that match a given request. The chosen // FlowSchema is among those with the numerically lowest (which we take to be logically highest) // MatchingPrecedence. Each MatchingPrecedence value must be ranged in [1,10000]. // Note that if the precedence is not specified, it will be set to 1000 as default. // +optional MatchingPrecedence int32`json:"matchingPrecedence" protobuf:"varint,2,opt,name=matchingPrecedence"` // `distinguisherMethod` defines how to compute the flow distinguisher for requests that match this schema. // `nil` specifies that the distinguisher is disabled and thus will always be the empty string. // +optional DistinguisherMethod *FlowDistinguisherMethod `json:"distinguisherMethod,omitempty" protobuf:"bytes,3,opt,name=distinguisherMethod"` // `rules` describes which requests will match this flow schema. This FlowSchema matches a request if and only if // at least one member of rules matches the request. // if it is an empty slice, there will be no requests matching the FlowSchema. // +listType=atomic // +optional Rules []PolicyRulesWithSubjects `json:"rules,omitempty" protobuf:"bytes,4,rep,name=rules"` }
type FlowSchema struct { metav1.TypeMeta `json:",inline"` // `metadata` is the standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata // +optional metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"` // `spec` is the specification of the desired behavior of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Spec FlowSchemaSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"` // `status` is the current status of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Status FlowSchemaStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"` }
type FlowSchemaSpec struct { // `priorityLevelConfiguration` should reference a PriorityLevelConfiguration in the cluster. If the reference cannot // be resolved, the FlowSchema will be ignored and marked as invalid in its status. // Required. PriorityLevelConfiguration PriorityLevelConfigurationReference `json:"priorityLevelConfiguration" protobuf:"bytes,1,opt,name=priorityLevelConfiguration"` // `matchingPrecedence` is used to choose among the FlowSchemas that match a given request. The chosen // FlowSchema is among those with the numerically lowest (which we take to be logically highest) // MatchingPrecedence. Each MatchingPrecedence value must be ranged in [1,10000]. // Note that if the precedence is not specified, it will be set to 1000 as default. // +optional MatchingPrecedence int32`json:"matchingPrecedence" protobuf:"varint,2,opt,name=matchingPrecedence"` // `distinguisherMethod` defines how to compute the flow distinguisher for requests that match this schema. // `nil` specifies that the distinguisher is disabled and thus will always be the empty string. // +optional DistinguisherMethod *FlowDistinguisherMethod `json:"distinguisherMethod,omitempty" protobuf:"bytes,3,opt,name=distinguisherMethod"` // `rules` describes which requests will match this flow schema. This FlowSchema matches a request if and only if // at least one member of rules matches the request. // if it is an empty slice, there will be no requests matching the FlowSchema. // +listType=atomic // +optional Rules []PolicyRulesWithSubjects `json:"rules,omitempty" protobuf:"bytes,4,rep,name=rules"` }
type FlowSchema struct { metav1.TypeMeta // `metadata` is the standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata // +optional metav1.ObjectMeta // `spec` is the specification of the desired behavior of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Spec FlowSchemaSpec // `status` is the current status of a FlowSchema. // More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status // +optional Status FlowSchemaStatus }
type FlowSchemaSpec struct { // `priorityLevelConfiguration` should reference a PriorityLevelConfiguration in the cluster. If the reference cannot // be resolved, the FlowSchema will be ignored and marked as invalid in its status. // Required. PriorityLevelConfiguration PriorityLevelConfigurationReference // `matchingPrecedence` is used to choose among the FlowSchemas that match a given request. The chosen // FlowSchema is among those with the numerically lowest (which we take to be logically highest) // MatchingPrecedence. Each MatchingPrecedence value must be ranged in [1,10000]. // Note that if the precedence is not specified, it will be set to 1000 as default. // +optional MatchingPrecedence int32 // `distinguisherMethod` defines how to compute the flow distinguisher for requests that match this schema. // `nil` specifies that the distinguisher is disabled and thus will always be the empty string. // +optional DistinguisherMethod *FlowDistinguisherMethod // `rules` describes which requests will match this flow schema. This FlowSchema matches a request if and only if // at least one member of rules matches the request. // if it is an empty slice, there will be no requests matching the FlowSchema. // +listType=set // +optional Rules []PolicyRulesWithSubjects }