概述 在 Kubernetes API 多版本和序列化 这篇文章中,介绍了API多版本的功能和实现原理,其中Codec就是用来做序列化工作的,它主要用在两个地方:一个是通过HTTP协议跟客户端进行交互时,会对传输的数据进行序列化和反序列化,将字节流类型的数据转换成对应的API对象,或者是将API对象转换成对应格式的数据返回给客户端;一个是用在存储层的,即API对象存储到数据库时,也需要经过编码的,即经过序列化,默认是存储成 protobuf格式的数据,然后从数据库读出来数据时,又会反序列化为对应的API对象,下面我们来分析下Codec的实现机制。
Serializer Serializer即是将API对象以某种数据格式进行序列化和反序列化,目前支持的数据格式有三种:json, yaml, protobuf,我们先来看看相关的接口定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 type Encoder interface { Encode(obj Object, w io.Writer) error Identifier() Identifier } type Decoder interface { Decode(data []byte , defaults *schema.GroupVersionKind, into Object) (Object, *schema.GroupVersionKind, error ) } type Serializer interface { Encoder Decoder } type Codec Serializer
Encoder接口中定义的Encode()方法是要将一个API对象以某种格式编码到输出中,而Decoder接口中定义的Decode()方法则是将字节类型的数据解码成某个版本的API对象,这两个编码解码的接口组合起来形成一个新的接口,叫Serializer,同时也叫 Codec。
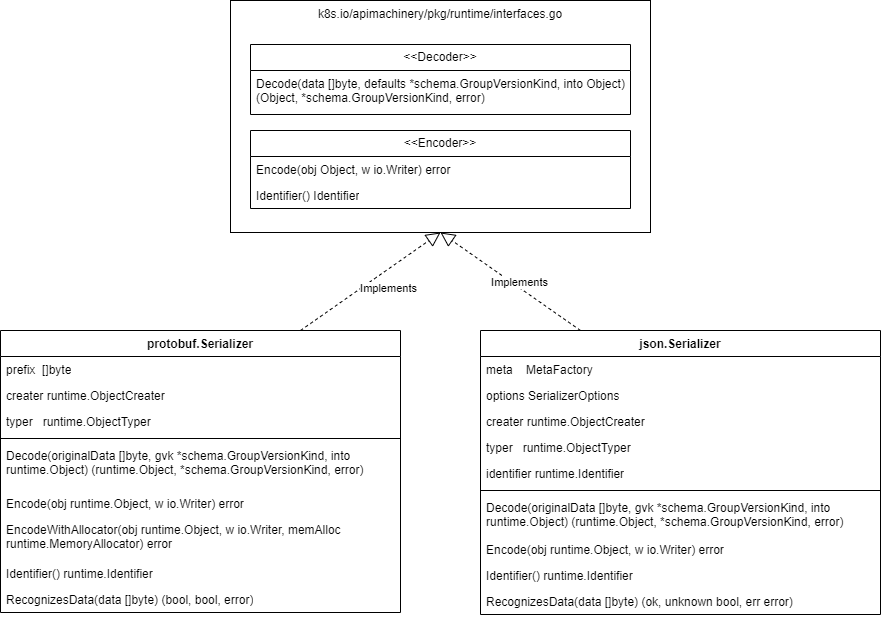
目前 Kubernetes 中有三种数据格式的Serializer,均实现了上面的接口,分别为json, yaml和protobuf,来看下他们的类图:
这几个Serializer定义在 k8s.io/apimachinery/pkg/runtime/serializer/ 目录下,分别实现了Json, Yaml和Protobuf数据格式的编码和解码操作,需要注意的是没有专门的Yaml Serializer的实现,因为Json跟Yaml的转换很容易,所以直接使用Json Serializer去实现了Yaml Serializer,具体json和protobuf是如何进行Encode和Decode的,这里我们不展开,这里只需要知道这几个Serializer的作用,做了什么事情即可。
CodecFactory 上面的接口中,为什么要再定义一个跟Serializer同名的接口Codec呢?Codec的注释有这么一句话,说明了它的作用:
Codec is a Serializer that deals with the details of versioning objects.
即Codec是专门用来处理多版本的API对象的序列化的,它除了需要做API对象的序列化操作之外,还需要做版本转换的操作,而上面介绍到的json/yaml/protobuf Serializer相对偏底层,只是做某个版本对象的序列化操作,Codec会引用Serializer做具体的序列化,然后再做版本转换。Codec既然跟对象版本有关,那肯定不同版本的API资源就要有不同的Codec了,所以我们就需要有个生产Codec的工厂类,即CodecFactory:
可以看到它实现了两个接口,NegotiatedSerializer 和 StorageSerializer,正好对应了本小节开头提到的Codec的两个作用:一个作用于HTTP,用来跟客户端交互,一个作用于存储,用来跟数据库交互,其中的 EncoderForVersion() 和 DecoderToVersion() 就是用来生产Codec的方法,来看看相关代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 func NewCodecFactory (scheme *runtime.Scheme, mutators ...CodecFactoryOptionsMutator) options := CodecFactoryOptions{Pretty: true } for _, fn := range mutators { fn(&options) } serializers := newSerializersForScheme(scheme, json.DefaultMetaFactory, options) return newCodecFactory(scheme, serializers) } func newCodecFactory (scheme *runtime.Scheme, serializers []serializerType) decoders := make ([]runtime.Decoder, 0 , len (serializers)) var accepts []runtime.SerializerInfo var legacySerializer runtime.Serializer for _, d := range serializers { decoders = append (decoders, d.Serializer) for _, mediaType := range d.AcceptContentTypes { ...... info := runtime.SerializerInfo{ MediaType: d.ContentType, EncodesAsText: d.EncodesAsText, Serializer: d.Serializer, PrettySerializer: d.PrettySerializer, StrictSerializer: d.StrictSerializer, } ...... accepts = append (accepts, info) if mediaType == runtime.ContentTypeJSON { legacySerializer = d.Serializer } } } ...... return CodecFactory{ scheme: scheme, universal: recognizer.NewDecoder(decoders...), accepts: accepts, legacySerializer: legacySerializer, } }
上面的代码显示了CodecFactory是如何创建出来的,比较重要的是 serializers := newSerializersForScheme(scheme, json.DefaultMetaFactory, options) 这行代码,这是去创建 json/yaml/protobuf 三种Serializer,然后在 newCodecFactory() 方法中将他们转成了 SerializerInfo 对象,最终将他们放到了CodecFactory的 accepts 属性中。还有个universal 属性,是把三种Serializer放到了一个列表里,然后组成了一个统一的decoder,即它可以解析三种格式的数据。
再来看看CodecFactory生产Codec的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (f CodecFactory) if encode == nil { encode = runtime.DisabledGroupVersioner } if decode == nil { decode = runtime.InternalGroupVersioner } return versioning.NewDefaultingCodecForScheme(f.scheme, encoder, decoder, encode, decode) } func (f CodecFactory) return f.CodecForVersions(nil , decoder, nil , gv) } func (f CodecFactory) return f.CodecForVersions(encoder, nil , gv, nil ) }
这几个函数接收的参数,都是接口类型的,Encoder和Decoder上面我们介绍过了,是用来做具体的数据格式序列化的,还有个GroupVersioner来看下:
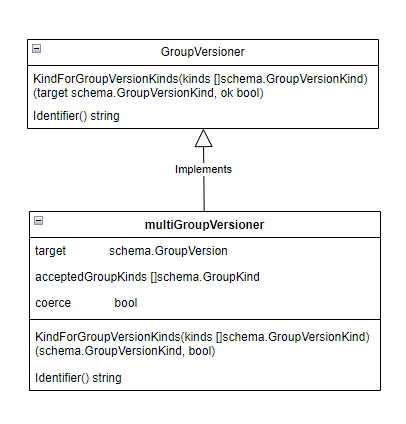
1 2 3 4 5 6 type GroupVersioner interface { KindForGroupVersionKinds(kinds []schema.GroupVersionKind) (target schema.GroupVersionKind, ok bool ) Identifier() string }
而实现了该接口的是一个叫 multiGroupVersioner 的结构体,位于 k8s.io/apimachinery/pkg/runtime/codec.go:
这个multiGroupVersioner的作用是什么呢?可以看看它里面的属性,有一个GroupVersion类型的target,然后有一个[]GroupKind类型的accetedGroupKinds,然后 KindForGroupVersionKinds() 方法的作用就是,当接收一个GVK列表时,看它们的GroupKind哪一个在acceptGroupKinds里,然后就会把它的Kind取出来,跟target组成一个新的GVK返回,即期望输出的Group和Version是固定的,就是target所指定的,只需要找到匹配的Kind即可,比如:
1 2 target=mygroup/__internal, acceptedGroupKinds=mygroup/Foo, anothergroup/Bar KindForGroupVersionKinds(yetanother/v1/Baz, anothergroup/v1/Bar) -> mygroup/__internal/Bar (matched preferred group/kind)
那它到底有什么用呢?要知道我们前面讲类型注册时,注册进scheme的类型,可能会对应多个GVK,即typeToGVK,multiGroupVersioner的作用就是在这,在进行版本转换时,已知一个类型,找到多个GVK时,能够唯一的确定一个GVK:
1 2 3 4 5 6 7 8 9 func (s *Scheme) copy bool , in Object, target GroupVersioner) (Object, error ) { var t reflect.Type t = reflect.TypeOf(in) t = t.Elem() kinds, ok := s.typeToGVK[t] gvk, ok := target.KindForGroupVersionKinds(kinds) ...... }
理解了GroupVersioner的作用,再来看看 CodecForVersions() 这几个工厂方法,就是指定了做序列化的encoder或者decoder,以及目标版本,然后构造了一个能够处理版本转换的 versioning.codec,它就是这个工厂方法生产出来的Codec,再来具体看看它:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 func NewDefaultingCodecForScheme ( scheme *runtime.Scheme, encoder runtime.Encoder, decoder runtime.Decoder, encodeVersion runtime.GroupVersioner, decodeVersion runtime.GroupVersioner, ) return NewCodec(encoder, decoder, runtime.UnsafeObjectConvertor(scheme), scheme, scheme, scheme, encodeVersion, decodeVersion, scheme.Name()) } func NewCodec ( encoder runtime.Encoder, decoder runtime.Decoder, convertor runtime.ObjectConvertor, creater runtime.ObjectCreater, typer runtime.ObjectTyper, defaulter runtime.ObjectDefaulter, encodeVersion runtime.GroupVersioner, decodeVersion runtime.GroupVersioner, originalSchemeName string , ) internal := &codec{ encoder: encoder, decoder: decoder, convertor: convertor, creater: creater, typer: typer, defaulter: defaulter, encodeVersion: encodeVersion, decodeVersion: decodeVersion, identifier: identifier(encodeVersion, encoder), originalSchemeName: originalSchemeName, } return internal } type codec struct { encoder runtime.Encoder decoder runtime.Decoder convertor runtime.ObjectConvertor creater runtime.ObjectCreater typer runtime.ObjectTyper defaulter runtime.ObjectDefaulter encodeVersion runtime.GroupVersioner decodeVersion runtime.GroupVersioner identifier runtime.Identifier originalSchemeName string }
codec实例中的encoder, decoder就是用来做具体序列化工作的json/yaml/protobuf Serializer,而creater, typer, defaulter均是scheme,encodeVersion, decodeVersion则是目标版本,还有convertor本质上也是scheme,只是在外面又包了一层,最终进行版本转换,调用的是scheme的UnsafeConvertToVersion()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 type unsafeObjectConvertor struct { *Scheme } func (c unsafeObjectConvertor) error ) { return c.Scheme.UnsafeConvertToVersion(in, outVersion) } func UnsafeObjectConvertor (scheme *Scheme) return unsafeObjectConvertor{scheme} }
来大致看看这个codec提供的Encode和Decode方法的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func (c *codec) error { ...... encodeFn := c.encoder.Encode ...... out, err := c.convertor.ConvertToVersion(obj, c.encodeVersion) ...... return encodeFn(out, w) } func (c *codec) byte , defaultGVK *schema.GroupVersionKind, into runtime.Object) (runtime.Object, *schema.GroupVersionKind, error ) { decodeInto := into obj, gvk, err := c.decoder.Decode(data, defaultGVK, decodeInto) if into != nil { if c.defaulter != nil { c.defaulter.Default(obj) } if into == obj { return into, gvk, strictDecodingErr } if err := c.convertor.Convert(obj, into, c.decodeVersion); err != nil { return nil , gvk, err } return into, gvk, strictDecodingErr } ...... }
可以看到Encode时,是先进行版本转换,然后再用encoder进行序列化,而Decode时,先用decoder进行反序列化,将字节类型的数据Decode到某一个版本的API对象中,然后再对其进行赋默认值操作,还有进行版本转换,转换到目标版本,版本转换就是调用到上面提到的 unsafeObjectConvertor,它又调用scheme中注册的各种版本转换方法进行转换了。
这个Codec虽然逻辑有点绕,但是总结来说,它做的工作就是利用Serializer + Scheme,来做序列化和版本转换的工作。
Codec使用场景 我们再来看看Codec是怎么使用的,前面提到过,Codec在两个地方被用到:一个是客户端通过HTTP协议跟APIServer交互时,需要进行Codec,一个是将API对象存储到数据库时,需要进行Codec,我们来分别看下这两个场景是怎么用Codec的,简单走下代码的流程即可(Code Walk-through)。
跟数据库进行交互 在 Kubernetes APIServer Storage 框架解析 这篇文章中,就介绍过API对象是怎么存储到数据库中的,其中,在为每个API资源构建etcd store时,会通过 DefaultStorageFactory 来为其构建存储配置,而Codec相关的逻辑就在这:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func (s *DefaultStorageFactory) error ) { chosenStorageResource := s.getStorageGroupResource(groupResource) storageConfig := s.StorageConfig codecConfig := StorageCodecConfig{ StorageMediaType: s.DefaultMediaType, StorageSerializer: s.DefaultSerializer, } if override, ok := s.Overrides[getAllResourcesAlias(chosenStorageResource)]; ok { override.Apply(&storageConfig, &codecConfig) } if override, ok := s.Overrides[chosenStorageResource]; ok { override.Apply(&storageConfig, &codecConfig) } codecConfig.StorageVersion, err = s.ResourceEncodingConfig.StorageEncodingFor(chosenStorageResource) codecConfig.MemoryVersion, err = s.ResourceEncodingConfig.InMemoryEncodingFor(groupResource) codecConfig.Config = storageConfig storageConfig.Codec, storageConfig.EncodeVersioner, err = s.newStorageCodecFn(codecConfig) return &storageConfig, nil }
codecConfig中会保存存储序列化相关的一些配置,StorageMediaType默认为 application/vnd.kubernetes.protobuf,而StorageSerializer则为 legacyscheme.Codecs,还有StorageVersion和MemoryVersion,分别表示该资源存储到数据库时使用的版本,以及加载到内存中使用的版本,我们来看看这两个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func (o *DefaultResourceEncodingConfig) error ) { if !o.scheme.IsGroupRegistered(resource.Group) { return schema.GroupVersion{}, fmt.Errorf("group %q is not registered in scheme" , resource.Group) } resourceOverride, resourceExists := o.resources[resource] if resourceExists { return resourceOverride.ExternalResourceEncoding, nil } return o.scheme.PrioritizedVersionsForGroup(resource.Group)[0 ], nil } func (o *DefaultResourceEncodingConfig) error ) { if !o.scheme.IsGroupRegistered(resource.Group) { return schema.GroupVersion{}, fmt.Errorf("group %q is not registered in scheme" , resource.Group) } resourceOverride, resourceExists := o.resources[resource] if resourceExists { return resourceOverride.InternalResourceEncoding, nil } return schema.GroupVersion{Group: resource.Group, Version: runtime.APIVersionInternal}, nil }
可以看到存储使用的版本,是通过scheme的PrioritizedVersionsForGroup()方法获得的,这个方法我们在scheme中介绍过,是获取该组中所有的版本,他们会按照优先级排序,排在第一位的是优先级最高的,一般是稳定版本是优先级最高的,这里取第0个值,即取的是版本优先级最高的版本,而内存版本则是内部版本,version为 __internal,所谓内存版本是指从数据库读出来原始的数据之后,要转换成的版本。
NewConfig()最终调用 newStorageCodecFn(codecConfig) 创建了Codec,我们来看看该方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 func NewStorageCodec (opts StorageCodecConfig) error ) { mediaType, _, err := mime.ParseMediaType(opts.StorageMediaType) if err != nil { return nil , nil , fmt.Errorf("%q is not a valid mime-type" , opts.StorageMediaType) } supportedMediaTypes := opts.StorageSerializer.SupportedMediaTypes() serializer, ok := runtime.SerializerInfoForMediaType(supportedMediaTypes, mediaType) if !ok { supportedMediaTypeList := make ([]string , len (supportedMediaTypes)) for i, mediaType := range supportedMediaTypes { supportedMediaTypeList[i] = mediaType.MediaType } return nil , nil , fmt.Errorf("unable to find serializer for %q, supported media types: %v" , mediaType, supportedMediaTypeList) } s := serializer.Serializer var encoder runtime.Encoder = s if opts.EncoderDecoratorFn != nil { encoder = opts.EncoderDecoratorFn(encoder) } decoders := []runtime.Decoder{ s, opts.StorageSerializer.UniversalDeserializer(), runtime.NewBase64Serializer(nil , opts.StorageSerializer.UniversalDeserializer()), } if opts.DecoderDecoratorFn != nil { decoders = opts.DecoderDecoratorFn(decoders) } encodeVersioner := runtime.NewMultiGroupVersioner( opts.StorageVersion, schema.GroupKind{Group: opts.StorageVersion.Group}, schema.GroupKind{Group: opts.MemoryVersion.Group}, ) encoder = opts.StorageSerializer.EncoderForVersion( encoder, encodeVersioner, ) decoder := opts.StorageSerializer.DecoderToVersion( recognizer.NewDecoder(decoders...), runtime.NewCoercingMultiGroupVersioner( opts.MemoryVersion, schema.GroupKind{Group: opts.MemoryVersion.Group}, schema.GroupKind{Group: opts.StorageVersion.Group}, ), ) return runtime.NewCodec(encoder, decoder), encodeVersioner, nil }
这里用到的方法基本上就都是我们前面介绍过的了,首先根据MediaType拿到对应的Serializer,然后创建了GroupVersioner目标版本,目标版本分别是codecConfig中的数据库存储版本和内存版本,然后通过StorageSerializer,即Codecs,即CodecFactory,使用EncoderForVersion(), DecoderToVersion()工厂方法,构建出带版本转换的encoder和decoder,最后这两者再组装成一个新的Codec返回:
1 2 3 4 5 6 7 8 9 10 11 type codec struct { Encoder Decoder } func NewCodec (e Encoder, d Decoder) return codec{e, d} }
这个codec就是简单的封装,只是为了对外提供统一的接口而已,它就是最终etcd store对API对象进行数据库存储和读取时,使用到的Codec了,例如下例中的codec便是这里NewCodec()创建出来的:
1 2 3 4 5 6 7 8 9 func decode (codec runtime.Codec, versioner storage.Versioner, value []byte , objPtr runtime.Object, rev int64 ) error { if _, err := conversion.EnforcePtr(objPtr); err != nil { return fmt.Errorf("unable to convert output object to pointer: %v" , err) } _, _, err := codec.Decode(value, nil , objPtr) ...... }
跟客户端进行交互 以GET某个API对象为例,在install GET请求的Handler时,构建了一个reqScope,它里面包含了跟序列化相关的变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (a *APIInstaller) string , storage rest.Storage, ws *restful.WebService) (*metav1.APIResource, *storageversion.ResourceInfo, error ) { ...... fqKindToRegister, err := GetResourceKind(a.group.GroupVersion, storage, a.group.Typer) ...... reqScope := handlers.RequestScope{ Serializer: a.group.Serializer, ParameterCodec: a.group.ParameterCodec, Creater: a.group.Creater, Convertor: a.group.Convertor, Defaulter: a.group.Defaulter, Typer: a.group.Typer, UnsafeConvertor: a.group.UnsafeConvertor, Authorizer: a.group.Authorizer, ...... Kind: fqKindToRegister, ...... } ...... switch action.Verb { case "GET" : var handler restful.RouteFunction handler = restfulGetResource(getter, reqScope) ...... } ...... }
fqKindToRegister, Kind为该API资源所对应的GVK,是scheme根据REST storage从注册的类型中识别出来的,reqScope中的 Serializer 实际上是 localscheme.Codecs,Creater, Convertor, Defaulter, Typeer, UnsafeConvertor实际上都指向的是全局的scheme,最终,构造了GET Handler的入口函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func getResourceHandler (scope *RequestScope, getter getterFunc) return func (w http.ResponseWriter, req *http.Request) ...... namespace, name, err := scope.Namer.Name(req) ...... outputMediaType, _, err := negotiation.NegotiateOutputMediaType(req, scope.Serializer, scope) ...... result, err := getter(ctx, name, req) ...... transformResponseObject(ctx, scope, req, w, http.StatusOK, outputMediaType, result) } }
getter()是从数据库中获取到对应name的API对象,并且进行了版本转换,转换成了内部版本,然后在 transformResponseObject() 方法中,又会根据outPutMediaType,以及scope中的Kind, Serializer等,将其转换为目标版本:
1 2 3 4 5 6 7 func transformResponseObject (ctx context.Context, scope *RequestScope, req *http.Request, w http.ResponseWriter, statusCode int , mediaType negotiation.MediaTypeOptions, result runtime.Object) ...... kind, serializer, _ := targetEncodingForTransform(scope, mediaType, req) responsewriters.WriteObjectNegotiated(serializer, scope, kind.GroupVersion(), w, req, statusCode, obj, false ) }
kind即为目标GVK,serializer即为codecs,实际来自scope中的Serializer。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func WriteObjectNegotiated (s runtime.NegotiatedSerializer, restrictions negotiation.EndpointRestrictions, gv schema.GroupVersion, w http.ResponseWriter, req *http.Request, statusCode int , object runtime.Object, listGVKInContentType bool ) ...... mediaType, serializer, err := negotiation.NegotiateOutputMediaType(req, s, restrictions) encoder := s.EncoderForVersion(serializer.Serializer, gv) request.TrackSerializeResponseObjectLatency(req.Context(), func () if listGVKInContentType { SerializeObject(generateMediaTypeWithGVK(serializer.MediaType, mediaType.Convert), encoder, w, req, statusCode, object) } else { SerializeObject(serializer.MediaType, encoder, w, req, statusCode, object) } }) } func SerializeObject (mediaType string , encoder runtime.Encoder, hw http.ResponseWriter, req *http.Request, statusCode int , object runtime.Object) ...... err := encoder.Encode(object, w) ...... }
encoder := s.EncoderForVersion() 则是调用了CodecFactory的工厂方法,创建了一个versioning.codec,然后调用 encoder.Encode() 进行序列化以及版本转换,然后将结果输出到HTTP ResponseWriter中,返回给客户端。
总结 Codec承担着序列化的工作,除了做序列化,还承担着调用scheme的逻辑进行版本转换的工作,所以Codec其实也是实现API多版本的重要机制,跟Scheme可以说是相辅相成。本篇文章分析了Codec的实现原理,本质上Codec是一个工厂方法类,它会为各个API资源进行版本转换和序列化创建一个实例,然后会用在两个场景上,一个是通过HTTP协议跟客户端进行交互,一个是跟数据库进行交互,同时本篇文章也对Codec在这两个场景的相关代码进行了简单的梳理。
如果想更好的理解Codec在这两个场景的作用,就需要了解APIServer的框架以及存储框架,推荐阅读下列文章: