Kubernetes Scheduler性能优化之Cache
背景
在Kubernetes Scheduler机制概览中就介绍过Cache的作用,它的主要作用是加速调度过程中查询pod和node等信息的速度,此外,还有Snapshot机制,即为了保持调度时数据的一致性,对缓存打的快照。
在查看Cache相关的代码时,发现Cache中有一些很奇怪的数据结构,看不明白为什么要做这样的设计,于是就追根溯源去查了下相关的issue和pr,了解了下当时的设计背景,发现针对scheduler的性能优化,还真是一个漫长的演进过程,从2015年就开始了,逐渐变成了现在这个样子,本篇文章就盘点一下,当年为提升scheduler性能而做的一些优化,顺便解释下Cache中那些奇怪的数据结构设计。
数据结构
我们先来看看现在cache和snapshot数据结构长什么样子:
Cache相关的数据结构:
1 | type schedulerCache struct { |
首先是为什么要有Cache?Informer中不是已经有了缓存了吗?难道那个还不能满足需求?其次,既然cache是做pod和node的缓存的,那么schedulerCache中podStates和nodes就很好理解了,使用Map来作为缓存的结构,通过哈希可以快速的找到某一个具体的node或者pod,但是令人迷惑的是headNode和nodeTree这两个结构,headNode是一个双向列表的第一个元素,通过next和prev指向下一个和前一个元素,这里竟然使用nodeInfo构造了一个双向链表,有map还不够吗?用意为何?此外nodeTree里面只保存了node的name,从map到slice的映射,这个又是做什么用的?
Snaphost相关的数据结构:
1 | type Snapshot struct { |
Snapshot是用来给Cache打快照的,那nodeInfoMap这个map还不够吗?为什么还有个nodeInfoList这样一个list?
原因探究
1. 为什么要引入Cache
带着这些疑问,我们将历史的年轮拨回2015年,先来看看为什么要引入Cache,相关的issue和pr如下:
- https://github.com/kubernetes/kubernetes/issues/18831
- https://github.com/kubernetes/kubernetes/pull/20669
- https://github.com/kubernetes/kubernetes/pull/21016
在该issue中,作者说的很明白,是因为当前的调度算法的复杂度是O(containers),甚至都不是O(pods)的,更别提O(nodes)了,在每一次调度时,都会遍历一遍该node上所有的containers,目的是为了计算出已有pod的request值,然后跟当前被调度的pod的request值进行比较,时间大部分被浪费在了遍历containers计算request值上了,因此改进的方法就是依赖informer的事件机制,动态的在本地再维护一份聚合之后的缓存,这样调度时,就可以直接获取到对应的数据,而不用实时计算了,可以看下缓存的node聚合之后的数据结构:
1 | // NodeInfo is node level aggregated information. |
可以看到,聚合的数据包括该节点上已经分配的ports信息,以及该节点所有pod的request之和,还有已经分配出去的cpu/memory资源之和等。
下面两个pr就是cache的实现,优化之后,30K个pod的调度延迟从200ms缩小到20ms,大大提高了性能,算法复杂度从O(containers)变成了O(nodes),即调度效率跟containers个数无关,跟nodes节点个数有关。
2. 为什么要引入Snapshot
Snapshot是对Cache打的快照,这个机制最早是在下面的PR中引入:
- https://github.com/kubernetes/kubernetes/pull/67308
- https://github.com/kubernetes/kubernetes/issues/67260
通过查看issue可以知道,这是在跑测试的时候,发现的缓存不同步,导致的调度失败,究其本质原因,是因为在某一个Pod调度过程中,其使用的cache发生了变化,尤其是在pod和node发生变更时,cache会实时更新,导致调度前后获取的信息不一致,才出现了问题。因此解决办法就是给Cache打一个快照,将Cache中的数据clone一份到Snapshot中,并且使用一个单调递增的值来标识这个快照的版本,即Snapshot中的generation字段,某个版本的Snapshot中的数据是不会发生变化的。
Snapshot发展到现在,已经将调度过程中,需要查询node和pod信息的地方,全都切换到了snaphost:
- https://github.com/kubernetes/kubernetes/issues/83922
- https://github.com/kubernetes/kubernetes/pull/83921
- https://github.com/kubernetes/kubernetes/pull/84293
切换到Snaphost之后,对性能有一个明显的好处,就是因为Snapshot是只读的,访问它的数据是不需要加锁的,这样在调度过程中,将很多地方实现了“无锁化”,将性能又提升了2倍。
3. Cache中为什么要用双向链表
所谓双向链表,就是schedulerCache结构中的成员变量:headNode *nodeInfoListItem所表示的结构,headNode只存储链表中的第一个元素,通过next和prev指针,来指向下一个和前一个元素,但是需要注意的是链表中存储的实际是nodeInfo的地址,并不是实际的数据。我们在上大学的时候,在数据结构课程上,就学习过双向链表这个结构,知道它的主要特点是体现在遍历上,即可以后序遍历,又可以前序遍历,并且插入删除节点,只是改变指针的指向,并没有实际移动数据,那这里引入双向链表又是为何呢?来看看引入双向链表的pr:
这个pr说,通过测试发现,在给cache打snapshot时,花费了较多的CPU时间,通过引入双向列表,将最近更新的node放到双向列表的列表头,再结合Snapshot Generation机制,大大缩减了给Cache打快照的时间,我们来看下给Cache打快照的核心代码逻辑变化:
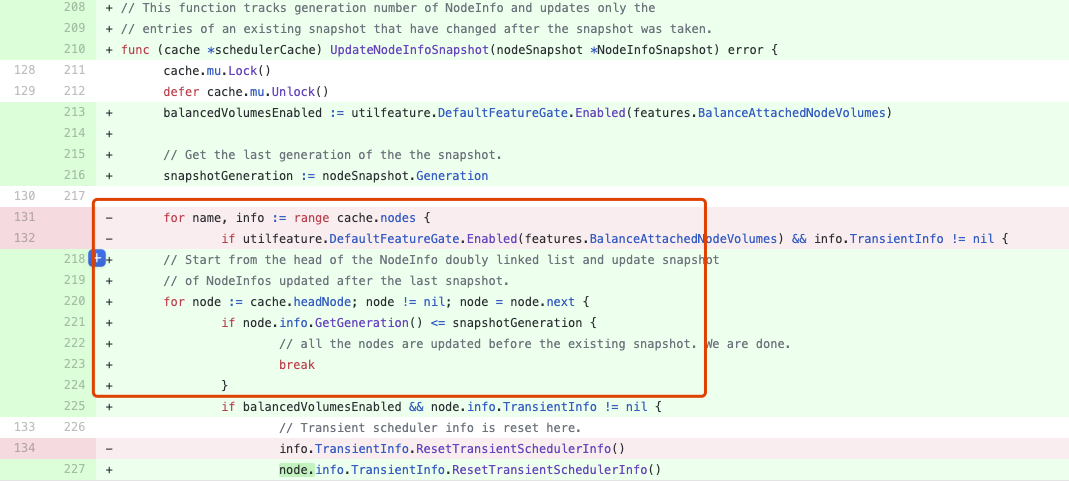
以前是遍历cache中的nodes列表,现在变成了遍历这个双向列表,而一但发现node中的generation值比snapshot中的generation值小的时候,就退出遍历,之所以能退出遍历,是因为所有对node的最近更新都被放到了链表头,而每次更新node,node中的generation值都会单调递增,如果在向后遍历node链表时,发现generation值比打快照时的值低了,那说明后面的node没有被更新过,就不需要再往后去更新了,只更新打快照之后,更新过的node就可以了。所以这里引入双链表,就是为了能够将“最近更新”过的Node放到一起,遍历时,只遍历这些更新过的node即可,而不用向以前一样,全量遍历整列表。当pod或者node有更新时,会将对应的更新之后的node节点放到链表头部位置,来看下这个移动的过程:
1 | func (cache *schedulerCache) moveNodeInfoToHead(name string) { |
通过局部遍历代替全量遍历,加快了Cache打快照的时间,性能提升了20%,在5000个node的规模下,调度10000个pod,延迟从8.5ms降低到了6.7ms。
不过,One more thing,还有一个未解之谜,就是为什么是“双向”列表?看代码这里遍历只用到了后序遍历,并没有找到在哪用到了前序遍历。如果只是后序遍历的话,那单向列表完全就满足需求了啊,用双向列表不是增加了复杂度吗?难道是作者在炫技?或者是后序可能还会用到后序遍历,这里只是留下了口子?迷惑的行为又增加了。。。
4. Cache中的nodeTree是做什么用的
nodeTree主要是考虑到node跨多zone而设计的,甚至还有pod针对zone的亲和性和反亲和性,所以在给某个pod选择合适的node时,node的遍历顺序还是很重要的,nodeTree主要决定了node的遍历顺序,其结构如下:
1 | // nodeTree is a tree-like data structure that holds node names in each zone. Zone names are |
所谓tree,其实就是zone到该zone所包含node列表的一个映射,遍历node列表时,是以轮询zone的方式进行遍历的,以Index来标识当前遍历到哪个zone或者node了,比如zone1(node1, node2, node3), zone2(node4, node5, node6),那么所谓”轮询zone”的遍历方式,就是以node1, node4, node2, node5, node3, node6的顺序进行遍历。
而因为调度时,都需要切换到使用snapshot里的信息,所以nodeTree也需要被打快照到Snapshot中,相关逻辑在下面的pr中实现:
但是该快照没有直接使用nodeTree这个结构,而是按照nodeTree的遍历顺序,将其变换成了一维的数组,即Snapshot结构体中的nodeInfoList,这样,在调度时,就可以直接遍历这个nodeInfoList了:
1 | allNodes, err := g.nodeInfoSnapshot.NodeInfos().List() |
通过将nodeTree打快照到Snapshot中,就可以进一步“无锁化”,将性能又提高了3%。
总结
从上面的性能优化过程可以看出来,引入Cache将性能提升了一个大台阶,在Cache基础上,又引入了Snapshot,逐步实现了“无锁化”的调度过程,将调度延迟从200ms降低到了6.7ms,满足了大多数集群规模对调度性能的要求。
Kubernetes Scheduler性能优化之Cache
https://hackerain.me/2020/12/20/kubernetes/kube-scheduler-cache.html