深度解析CephX原理—调节NTP时钟的困境
背景
我们知道CephX是Ceph中的认证机制,防止系统被未授权客户端访问,以及防止被中间人攻击。之所以会去研究CephX,是因为近期有一个客户有一个需求,就是要调整整个Ceph集群的时钟,跟公司内部的一个NTP Server保持时间同步,该客户有多套Ceph集群,有大有小,大的集群有上千个OSD,客户端有上万个。Ceph集群都是5年前搭建的,运行的版本还是0.94.7的Hammer版,现在跑着公司的核心业务,目前NTP使用的是Ceph集群内部的一个NTP Server,这些集群跟要切换到的NTP Server的时钟最多有差30多分钟的,而且是落后30分钟,调整时钟,相当于是将整个集群往前调快时间,而且一定不能影响业务。
我们都知道Ceph是一个对集群时钟要求很高的系统,当集群时间不同步时,会出现很多问题,严重的,会直接影响客户端的正常IO,在我们多年的运维经历中,遇到过一两次这样的问题。其中CephX就是这样一个对时间要求比较高的子系统,因为其内部会维护很多认证需要的secret,都有过期时间,而且是分散在整个集群中的,即客户端,osd,mon等都依赖这些secret,当集群内部时钟不一致时,组件之间判断secret的过期时间就会出现紊乱,从而产生认证错误,即bad auth,情况好点的,可能会导致osd卡很久无法正常启动,严重的,会直接导致客户端产生大量的slow request,而且会block很长时间,影响客户端IO。
跟时钟密切相关的还有另外一套子系统,即heartbeat心跳,该机制是判断集群健康状态的生命线,当集群时钟不同步,会对心跳判断组件是否正常产生影响,会导致osd被误报为down,触发pg peering,以及osd flapping等异常现象,影响集群的正常IO。
本来给客户的建议是依赖ntpd的机制,让其慢慢往前调节时间,但是由于时钟差的有点太多,这个时钟同步太漫长了,可能要花费数个月的时间,才会同步30分钟,客户无法接受这个方案,寻求有没有快一些的方案,或者能否一步到位的。于是我们就开始了漫漫征程,开始做测试,研究代码,于是有了这篇文章。
测试
为了尽量能够暴露问题,我们做的测试环境,是一个准生产环境,是一个内部的开发测试环境,对可用性没有生产环境那么高,但是环境很大,客户端压力也很大,有将近900个osd,5000台虚拟机,15000个云硬盘。
方案一
因为一开始我们并没有考虑到时钟会对cephx产生影响,只考虑了heartbeat的影响,所以一开始提出的测试方案就是先停掉服务,然后同步时间,然后再启动服务。先从mon开始做,因为3个mon是高可用的,所以挨个做mon节点,停mon,同步时间,启动mon,三个mon做好之后,再逐个节点做osd,停某个节点的所有osd,同步时间,启动osd。
但是在做完3个mon节点,在做第一个osd节点的过程中,时间大概有1个多小时,观察到集群产生了大量的slow request,大概持续了十几分钟,才消失,ceph health detail 发现slow request发生在了很多osd上,不是某个osd。事后分析日志,发现产生slow request的osd只发生在已经做过变更的OSD上,没有做过变更的OSD,并没有产生slow request,而且产生slow request的osd上,在故障时间点,都报出了大量的如下日志:
1 | 2019-11-16 22:58:04.552670 7f326b1d9700 0 auth: could not find secret_id=32482 |
看样子,是因为osd没有找到某个secret,导致客户端来的请求,认证没有通过,本次请求失败,客户端不断反复请求,从而产生了大量slow request,而且有的请求卡到了400秒,这个故障时间已经严重影响到了正常业务。
分析cephx的认证机制,为了防止中间人进行攻击,用来加密认证信息的secret并不是使用永久的secret,而是使用的会周期性删除的secret用来做认证,ceph中叫做RotatingSecrets,在一个RotatingSecrets中,始终保持有3个secret,如下图:
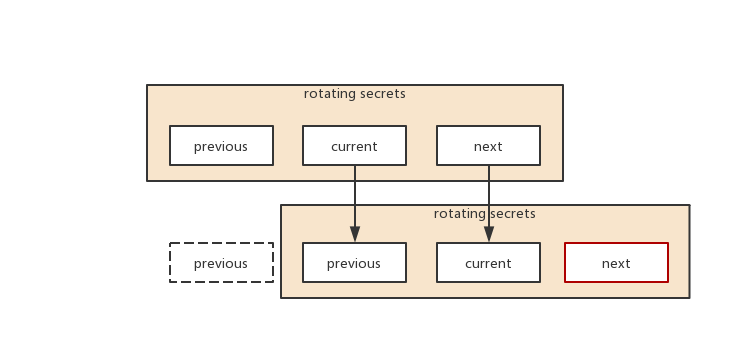
current是当前正在使用的secret,previous是之前使用的secret,next是下一个将要使用的secret,当current过期了之后,previous会被删除,current就变成了previous,next就变成了current,然后会再生成一个新的next。客户端也会不断的renew自己的认证信息,该认证信息,在ceph里叫做ticket,ticket里指明了客户端需要使用哪个secret来进行认证,即上面日志中的secret_id,之前使用的是previous,过一定周期之后,会自己切换成current,previous的存在,是为了保证客户端能够在较大的时间窗口内,renew自己使用的ticket,更换secret。
rotating secret的过期时间默认是1个小时,即1个小时rotating一次,因为我们本次调整的时间是30多分钟,而且是向前调整,即加快时间,这会导致一部分osd的current的secret被提前过期掉,导致触发rotate操作,所以previous就被提前删除了,然后导致很多还在使用这个previous的客户端出现了认证问题,影响了业务,直到客户端触发renew操作,切换了secret之后,才会恢复正常。
控制rotating secret过期时间的一个参数,叫做 auth_service_ticket_ttl,单位为秒,默认 60*60,即1个小时。于是我们调整了测试方案,计划加长这个参数,让rotating secret的过期时间放慢,给客户端足够的时间进行切换,所以有了方案二。
方案二
调整 auth_service_ticket_ttl,该参数控制rotating secret的过期时间,默认为1个小时,即3600秒,可以将该参数调整为2小时,即7200秒,延长secret的过期时间。延长一个小时,这样在时间往前调整30分钟的情况下,肯定可以有足够的时间buffer让客户端来更新自己使用的secret,该方案的大致步骤如下:
动态调整mon和osd的ttl参数
1
2ceph tell mon.* injectargs --auth_service_ticket_ttl 7200
ceph tell osd.* injectargs --auth_service_ticket_ttl 7200修改ceph.conf的配置,添加下面的配置项:
1
2[global]
auth_service_ticket_ttl = 7200等待2小时,等待secret以及ticket renew
开始按照以前的操作重启mon和osd
然而在执行完步骤1和2,在步骤3的等待2小时的过程中,发现大概过了1个小时的时间,就观察到有大量的slow request产生了,查看产生slow request的osd的日志,发现竟然还是因为认证失败导致的,即又产生了跟方案一中一样的故障现象,即大量的bad auth。
这是怎么回事呢?理论上,加长了ttl,不是应该rotating secret的速度放慢了吗?而且为什么总是过了一段时间,即一个小时左右,才会产生slow request?这里面肯定还有什么机制没有搞清楚,所以带着这些问题,我们来仔细分析下CephX的认证原理。
原理
众所周知,Ceph是一个去中心化的存储系统,意味着客户端会直接跟最终的存储设备直接交互,具体的,即客户端会直接跟osd交互,而客户端和osd可能都有成百上千,他们之间的交互认证该如何设计呢?Ceph参考了Kerberos的设计思路,引入了认证中心的概念,即由Mon充当认证中心,客户端和OSD在启动以及后续的运行过程中,都会不断跟Mon进行交互,Mon会向客户端和OSD签发他们能够彼此进行认证的标识和密钥,客户端带着这个标识,去向OSD进行认证,OSD使用这个标识去找到对应的密钥,如果能够使用这个密钥成功解密客户端发来的认证信息,并且比对相关的信息正确,则认为认证成功,可以进行后续的数据传输操作。
上述的过程,被Ceph实现为了一个名为CephX的协议,为了更好的理解它,我们先介绍该协议中几个重要的概念:
- keyring,这个概念我们比较熟悉,在部署Ceph的时候,这个是必须生成的,每一个OSD和客户端都会有一个对应的keyring,可以用
ceph auth list命令看到,里面包含了一个密钥和该客户端相应的权限信息,keyring在CephX中称为permanent secret,即是固定不变的密钥,它的主要作用其实是在建立客户端和Mon进行连接认证时所用,当认证通过后,后续的数据传输阶段就不再使用了,除非重新进行认证连接。 - secret,这里指的既是上面提到的rotating secrets,即
临时的secret,每一个rotating secrets中包含了3个secret: previous, current, next,每一个secret是有一定有效期的,当过了有效期,会被逐渐rotate掉,即会被逐渐删除掉,这个动态的secret的设计,主要是用来数据传输阶段,防止中间人进行攻击而设计的。rotating secrets由mon进行生成和维护,然后下发给osd,供osd在后续跟客户端的数据传输过程中,进行认证使用,在CephX中,也被称为service secret。 - ticket,主要是用来标识客户端信息的,客户端初次向mon发起认证请求时,如果认证通过,mon会签发给该客户端一个ticket,该ticket中包含客户端的标识,过期时间,以及session key,mon会使用当前的secret,来加密ticket,然后将当前的secret的id附在ticket中,发送给客户端,客户端对ticket是透明的,即客户端不需要知道ticket的具体内容,该内容只是在客户端向osd发起请求时,由OSD端根据secret id,找到对应的secret,进行认证使用的。需要注意的是,ticket跟secret一样,都是有有效期的,都不是固定的,都在周期性的变化。
- session key,它的主要作用,是在认证通过之后,用来加密传输数据的校验码的,Ceph在传输数据的时候,并没有对传输的数据进行加密,仅仅是对传输的数据,计算了CRC循环校验码,然后对CRC用session key进行了加密,数据发送到OSD后,OSD对CRC进行解密,若解密成功,再按相同的校验算法进行一遍CRC的校验,如果匹配,则可认为数据传输正确,该方法主要是为了防止数据被中间人篡改,并不能起到加密的作用。
在CephX的协议中,定义了4种服务: Auth, Mon, OSD, MDS。Auth即认证服务,由Mon提供,即Mon作为认证中心,对客户端提供跟其他服务认证相关的服务;Mon服务即是提供Monitor本身具有的功能的服务,如向客户端提供monmap等;OSD服务就是为客户端提供最终读写操作的服务;MDS是提供文件系统相关的服务。客户端在启动的时候,首先会向Mon发起认证请求,经过多次交互,认证通过后,会从Mon那里拿到相应的认证信息,即ticket,然后就可以带着认证信息,向最终服务发起请求,这些服务端会去验证认证信息,如果通过,则可以进行后续操作。每一个客户端都通过MonClient这个类来提供跟认证相关的逻辑。
下图为一个客户端从发起认证,到最后跟OSD进行数据交互的时序图:
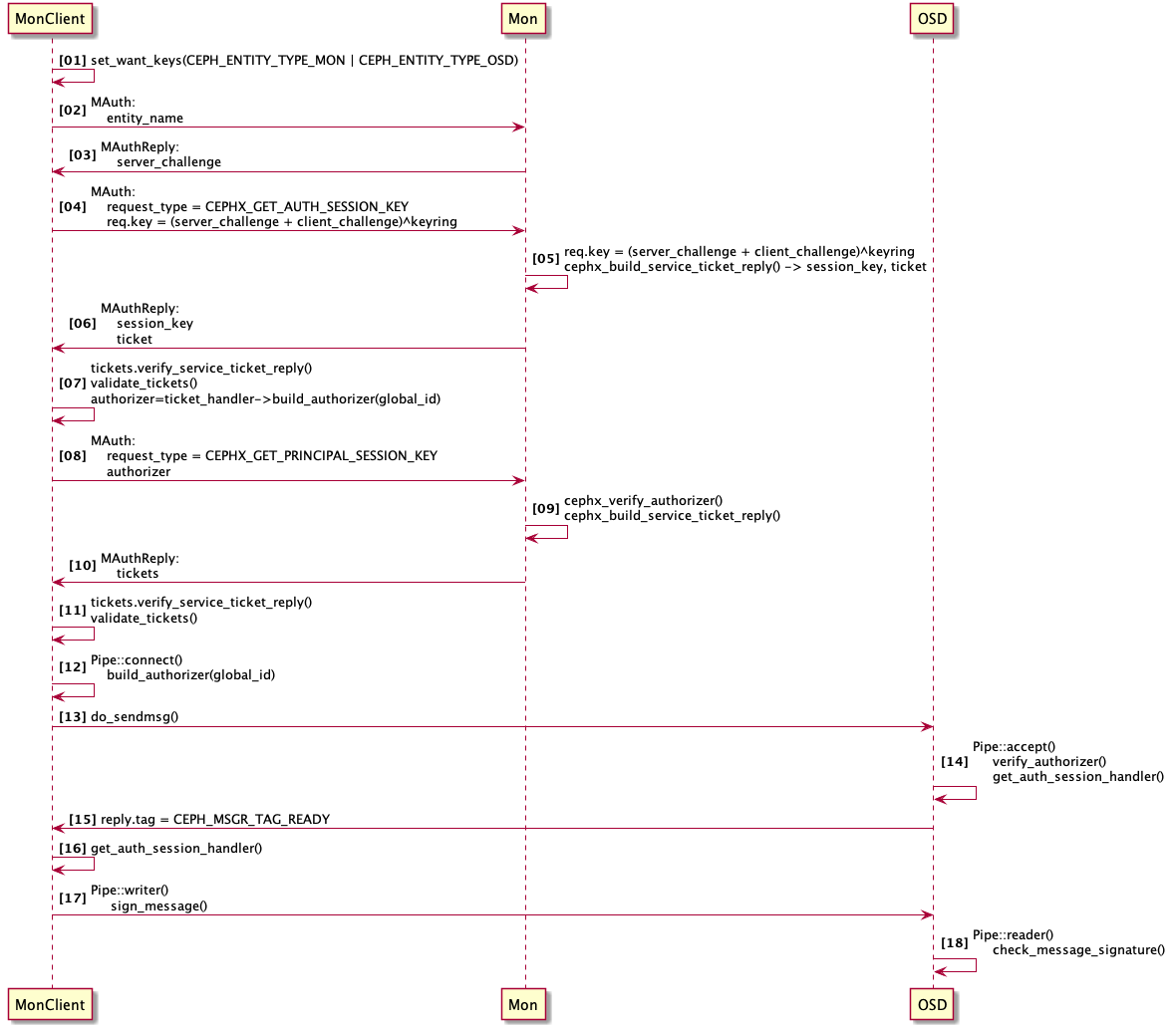
可以看到,整个过程还是非常复杂的,大概分为三个阶段:
客户端跟Mon进行认证
上图中的1-11步,都是客户端在跟Mon进行认证交互,经过多次交互,客户端建立起自己的认证体系,主要是从Mon获取到了针对各个服务的ticket,因此需要注意,客户端维护的不是一个ticket,而是多个ticket,即针对每一个服务有一个ticket。客户端需要哪些ticket,是在客户端启动的时候,由上图中的第一步,即set_want_keys()函数就确定好了的,比如RadosClient,因为它要读写数据,会跟Mon和OSD都交互,因此就会设置自己的want keys为: Mon, OSD,如果是打开了cephx认证,还会默认将Auth添加到want keys中,因此一个RadosClient需要三个ticket。
关于这部分的实现方式,Ceph中运用的非常经典,值得好好推敲,每一个客户端都维护了want, have, need这三个无符号整形变量,即uint32,用这三个变量的位操作来标识当前客户端对某种类型ticket的需求状态:
- want,就是客户端期待有什么类型的服务
- need,就是客户端有了某种类型的服务,但是需要更新或者是还没有某种类型的服务,需要去获取的
- have,就是已经有了某种类型的服务,还在有效期内
Ceph中定义了如下的类型变量:
1 | #define CEPH_ENTITY_TYPE_MON 0x01 |
比如 set_want_keys(CEPH_ENTITY_TYPE_MON | CEPH_ENTITY_TYPE_OSD) 就是将want中通过 want |= service_id 位或操作,将want中的相应位置为1,代表需要某一个类型的服务。在整个认证过程中,会用到如下的组合:
1 | 37(10进制)= CEPH_ENTITY_TYPE_AUTH | CEPH_ENTITY_TYPE_OSD | CEPH_ENTITY_TYPE_MON |
因此在客户端和Mon进行认证的过程中,会看到如下的debug日志:
1 | cephx: validate_tickets want 37 have 32 need 5 |
表示的意思就是当前客户端希望有AUTH, MON, OSD这3个服务的ticket,当前已经有了AUTH服务的ticket,但是还需要OSD和MON的ticket。通过这种机制,客户端在初次认证,以及后续的ticket更新过程中,可以高效的维护自己的ticket状态,没有的就向Mon去获取,有了的快过期的了,就向Mon去申请新的ticket。
关于ticket,内部由一个叫做 CephXTicketHandler 的结构体对某一个ticket进行封装,而 CephXTicketHandler 又被一个叫做 CephXTicketManager的结构体进行管理,比如获取针对某一个类型服务的TicketHandler,或者是验证被它管理的TicketHandler是否过期等。CephXTicketHandler结构体的内容如下:
1 | CephXTicketHandler |
1 | CephXTicketBlob |
ticket是由Mon签发给客户端的,即ticket在Mon端就确定好了该ticket的过期时间,重新renew的时间,为其生成了一个随机字符串session_key,然后通过对应服务的service_secret(即rotating secret,Mon针对每一类型的服务,是有单独的secret的)对ticket的内容进行加密,最终发送给客户端的。
上图中,4-6步,获取到了AUTH服务的ticket,在此基础上,再通过7-11步获取到了MON和OSD服务的ticket。
客户端跟OSD进行认证
上图12-16步,是在客户端在跟Mon交互认证完成之后,跟OSD进行认证交互的过程,即客户端通过Messenger跟OSD建立连接的过程中,需要先通过认证才可以。实现逻辑位于客户端的Pipe::connect(),以及服务端的Pipe::accept()函数中,在客户端通过build_authorizer()函数将OSD服务对应的ticket封装在一个叫CephXAuthorizer的结构体中:
1 | auth.h / AuthAuthorizer |
并使用session_key加密这个CephXAuthorize,然后发送给OSD服务端,OSD服务端通过verify_authorizer()方法验证该CephXAuthorizer,验证的过程首先会使用对应的service_secret对ticke进行解密,然后再用session_key解密出CephXAuthorize,若这两步都解密成功,则认证通过,客户端跟OSD建立起了Messenger连接。
这里需要说明一点的是OSD端的service_secret是在OSD启动的时候,从Mon端获取到的,后续OSD会不断的检查自己的service_secret是否过期,如果过期,则会去Mon再重新申请新的secret,而ticket是在Mon端使用对应类型服务的secret进行签发,下发给客户端的,因此在这里OSD可以使用自己的secret对ticket进行验证。
客户端跟OSD进行数据交互
即上图中的17-18步,在客户端跟OSD建立起连接之后,就可以传输数据了,通过Messenger的writer()和reader()实现。如前所述,Ceph在传输数据的时候,并没有对传输的数据进行加密,仅仅是对传输的数据,计算了CRC循环校验码,然后对CRC用session key进行了加密,数据发送到OSD后,OSD对CRC进行解密,若解密成功,再按相同的校验算法进行一遍CRC的校验,如果匹配,则可认为数据传输正确。该部分逻辑,是在CephXSessionHandler中的sign_message()和check_message_signature()方法实现的。
通过以上的认证交互过程,最终,客户端和服务端整体的状态图如下:
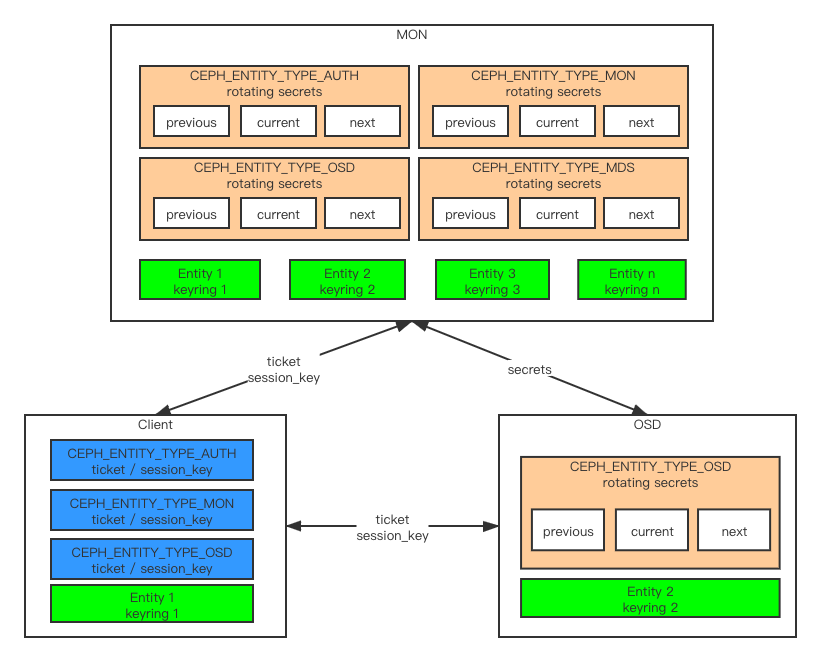
Mon在启动的时候,会为每种服务生成一组rotating secrets,即分别为Auth, Mon, OSD, MDS各生成一组rotating secrets,因为这些rotating secrets都是临时的,都有过期时间,Auth服务的过期周期由 auth_mon_ticket_ttl 参数控制,默认为12小时,而其他服务的过期时间则由 auth_service_ticket_ttl 控制,默认为1小时,然后Mon会在它的tick()函数中,不断的检查这些服务的secrets是否过期,如果过期,则进行rotate操作,删掉previous,生成新的next。此外各个entity(包含client和osd)的keyring会注册进mon中,即Mon是能知道整个集群的所有entity的keyring的。
OSD在启动的时候,也会作为一个客户端向Mon进行认证,但是因为它同时也是服务端,所以额外的,它会获取到OSD类型的rotating secrets,保存到自己的内存中,后续其他客户端来进行认证的时候,OSD就会使用这一组rotating secrets对客户端进行认证。因此,需要注意,所有的相同类型的服务端,获取到的rotating secrets都是同一份,都是同Mon获取到的同一份secrets,即所有OSD中的rotating secrets都是一样的。类似的,OSD也会在本地的tick()函数中,不断的check自己的rotating secrets是否过期,即将current的secret的过期时间跟本地的时间比较,如果过期,则向Mon发起申请新的secret的请求。
客户端在启动的时候,会向Mon进行认证,就像前面时序图中描述的流程那样,经过认证,获取到了对应的ticket,需要注意的是,因为客户端要跟多个服务端进行交互,针对每种服务端,客户端会向Mon各申请一个ticket,维持在自己的内存中,并且在客户端的tick()函数中,不断的check这些ticket是否过期,ticket在过期之前会提前去申请,即客户端会不断的将ticket中的renew_after字段跟本地的时间进行比较,renew_after的值为过期时间减去ttl/4,即 renew_after = expires; renew_after -= ((double)msg_a.validity.sec() / 4);,即如果是OSD服务,则是提前15分钟进行renew操作,如果达到了需要renew的时间点,则会向Mon发起申请新的ticket的请求。
客户端的认证过程,可以通过rados bench命令打开debug_auth选项,来看下这个过程:
1 | [root@portal ~]# rados bench 1 write -p rbd --debug_auth=20 2>&1 |
原因分析
了解了以上原理,就可以分析在 测试 中的两个方案为什么会出现问题了,在客户端数量很多的情况下,会不断的有客户端的ticket过期,然后再申请新的ticket,而此时如果动态加上了ttl的时间,那么会有一部分客户端申请到的ticket的过期时间变长了,即renew变慢了,而此时osd的rotating secret,因为共有3个secret: previous, current, next,由于其是在改变ttl参数之前就已经生成了的,其过期时间是已经确定了的,即1小时rotate一个,所以其rotate的速度并没有相应的变慢,所以会存在一个时间窗口,当1小时后,current过期了,previous就会被rotate掉了,而此时还在用previous的客户端并没有提前去申请新的ticket,而导致这部分客户端去访问对应的osd时,出现了bad auth。
与之类似的,调整NTP时钟,因为是往前调,相当于加快了mon的rotate secret的时间,osd的rotating secret的过期时间也对应加快了,从而osd向mon申请了新的rotating secret,但此时一部分客户端还在使用之前申请的ticket,其renew的时间并没有发生变化,还是按以前的时间在renew,相当于是部分客户端ticket renew变慢了,从而出现了一个窗口,导致osd找不到客户端发来的secret_id了,从而出现了bad auth。
所以,基于以上原理,重启mon和osd,都无法避免bad auth,唯一不影响业务的方案,就是减小调整时间的幅度,因为客户端会提前15分钟进行renew,申请新的ticket,所以最大的调整窗口期为15分钟,为了保险起见,可以调整为10分钟,即每一个小时,将整个集群的时间往前调整10分钟。同时,为了确保心跳不导致osd down,可以将该10分钟在每个小时内,分多次进行调整,比如每分钟调整10秒钟,1小时调整60次,将集群慢慢向前进行同步。
最终方案
按照上述思路,发现在调整5秒的情况下,都有osd down,并且是osd进程挂掉了,如下:
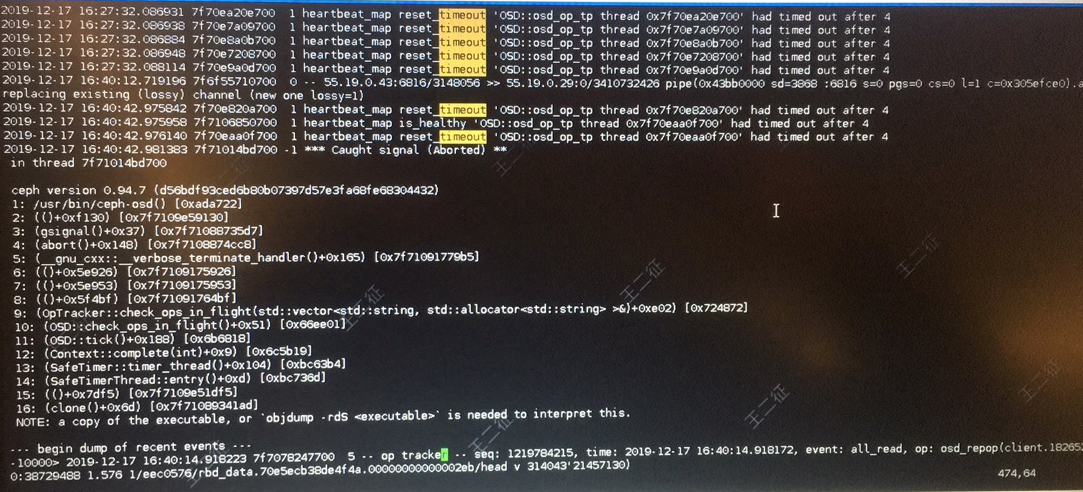
首先是报错:
1 | heartbeat_map reset_timeout osd_op_tp thread had timed out after 4 |
意思是在4秒后,op线程超时报错了,该超时是因为在0.94.7版本的ceph代码中在,有部分硬编码,超时时间不能超过4秒,相关逻辑如下:
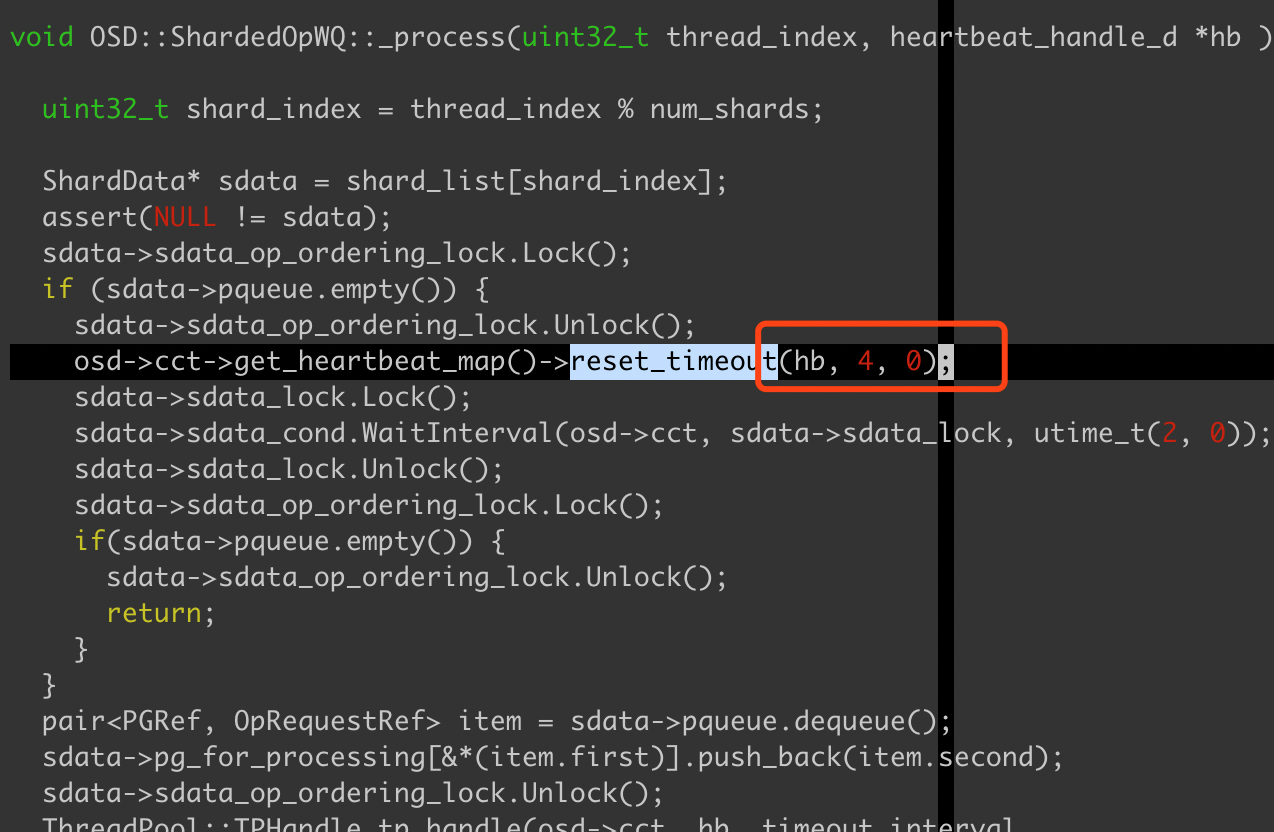
在pqueue为空的情况下,即队列中没有pg,会reset_timeout为4秒,并且是硬编码的,不能修改,因为我们往前调整5秒,正好超过了这个硬编码的timeout,所以报这个错了,因为是硬编码没法修改,目前我们调时间只能调4秒以内了,因此安全的方案是以2秒为单位往前调整。
此外,上面的报错日志中,发生了osd挂掉的情况,查看日志,发现是check_ops_in_flight()中的相关逻辑,出现了异常导致退出,看日志是被发送signal信号退出的,并不是因为超时,或者是超时自杀,看代码逻辑,可能是因为往前调整时间,导致了ceph代码中,有空指针等程序异常,没有被ceph catch到,导致异常退出了。跟该逻辑相关的配置参数是 osd_op_complaint_time,该参数来确定一个io被判断为slow request的范围,观察客户环境,ssd介质的OSD配置的1秒,sata介质的配置的是5秒,而默认值是30秒,将该值调整为10秒之后,没有再发生OSD down的情况。
因此,根据上面的测试以及分析结果,最终的方案,就是调整osd_op_complaint_time的时间为10秒,然后以2秒为粒度,向前调整时间,1个小时最多不要超过10分钟。
总结
本篇文章,从客户的一个变更需求入手,分析了CephX的原理,虽然实现方式非常复杂,但是理清了各个组件之间的关系,整体逻辑还是比较好理解的,然后根据此原理,给出了不影响业务的切实可行的变更方案,但是也可以看到,为了不影响业务,变更时间也将会非常长,如果调整30分钟的话,1分钟调整2秒,1小时只能调整2分钟,30分钟,至少需要花费15个小时,因此,建议各位运维同仁,把 集群NTP时钟 这一项加到你的checklist中,在集群刚开始搭建的时候,就最好确定好集群的时钟,多花一分钟问下领导NTP的事,会为自己免去至少一个月的痛苦时光,边开飞机边修飞机的事情,尽量少干吧。
深度解析CephX原理—调节NTP时钟的困境