Kubernetes APIServer 机制概述
断断续续研究Kubernetes代码已经大半年时间了,一直在看APIServer相关的代码,因为API是一个系统的入口,是所有功能对外的抽象体现,同时也是其它组件都依赖的一个组件,处于非常核心的地位,因此它被社区进行了精心的设计,了解了它,就可以顺藤摸瓜去了解其他核心的功能。不过,经过这么长时间的摸索,发现Kubernetes的代码是真心复杂,明显感觉要比看OpenStack的代码费劲多了,感觉它的复杂性主要来自于以下几个方面:
- Kubernetes经过这么多年的发展,功能不断在扩展,不断地在复杂化,为了应对这种复杂化,代码也不断被重构和抽象,逐渐往模块化,插件化,自动化发展,典型的像apimachinery这个库,就是api层面最高层的抽象,如果不结合它的使用,单看这个库的代码,几乎是看不懂的,而且往往Kubernetes里面一个结构体的内容非常多,结构体里又嵌套多层结构体,围绕这个结构体又有一堆的方法,信息量巨大,此外代码中还有大量的magic code,不了解背景的话,很难理解为什么写这段代码。
- Kubernetes是用Golang写的,Golang是没有类似于C++, Java, Python那种类的概念的,也没有继承,多态,这种面向对象的编程方式,它的抽象方式,只有一种,就是Interface,以及实现了这个Interface的结构体,所以面对这种复杂的项目,代码组织是非常凌乱的。
- 毕竟Golang没有Python/Java这种编程语言老牌,Kubernetes项目中,用到的第三方库比较少,很多都是自己写的库,典型的像APIServer中,处理REST请求的库,虽然使用了第三方go-restful,但还是自己开发了一个NonGoRestfulMux,因为go-restful不能满足它的一些功能要求,与之类似的,还有API对象的序列化,以及对数据库的操作,都是自己写的库,这在Python里面都有成熟的强大的库,可以屏蔽掉这些细节,这些都显著增加了它的复杂度。
面对它四五百万行的代码量,真心感觉罗马不是一天建成的。单看APIServer,里面有各种各样的机制,比如authentication, authorization, admission, storage, api group, extension, metric, log, audit, client, informer等等,本系列文章,打算介绍下Kubernetes APIServer一些主要机制的实现方式,包括如下几个方面:
- APIServer是怎么run起来的
- APIServer是怎么跟数据库打交道的
- APIServer中定义的API的Group和Version是怎么组织的
- APIServer的扩展机制是怎么实现的
- APIServer的序列化机制
本篇文章,主要介绍下APIServer的大致脉络,即上面提到的第一个问题,APIServer是怎么run起来的。本质上,APIServer是使用golang中net/http库中的Server构建起来的,所以在这之前,我们先来看看golang里面的http Server是怎么使用的。下面是一个非常简单的例子:
1 | package main |
Handler是其中一个非常重要的概念,它是最终处理HTTP请求的实体,在golang中,定义了Handler的接口:
1 | type Handler interface { |
凡是实现了ServeHTTP()方法的结构体,那么它就是一个Handler了,所以上面定义的MyHandler结构体因为实现了ServeHTTP()方法,所以它是一个Handler,可以用来处理HTTP请求。然后在main()方法中,实例化一个MyHandler的对象,将其通过Handler参数传给了http.Server,然后ListenAndServe(),将Server运行起来,这样就完成了一个简单的HTTP Server了。这其实就是Kubernetes APIServer的骨架了,只不过它有非常复杂的Handler。
宏观上来看,APIServer就是一个实现了REST API的WebServer,最终是使用golang的net/http库中的Server运行起来的,数据库使用etcd,而且目前是唯一支持的后端存储,所以简单理解,APIServer所做的事情,就是对数据库的增删查改。但是,作为一个功能完备的Web Server,不能只有对数据库的增删查改,还需要比如:对外暴露API,必须要有认证和授权,而且Kubernetes为了能够让管理员更进一步控制API,还实现了其独有的Admission机制,此外,通过group和version(组和版本)来组织其API对象,为了保持兼容性,多个版本的对象可以共存,还有其扩展机制,即著名的CRD和Aggregation,等等这些,让APIServer丰满和复杂起来。APIServer启动的过程,就是对这些机制setup的过程,其大致流程如下图所示:
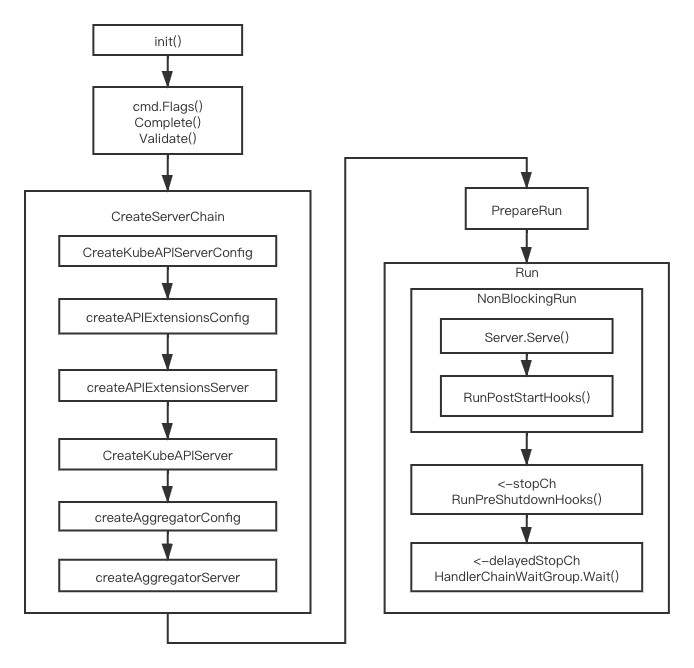
init()是在main()函数启动之前,就进行的一些初始化操作,主要做的事情就是注册各种API对象类型到APIServer中,这个后续会讲到。
随后就是进行命令行参数的解析,以及设置默认值,还有校验了,APIServer使用cobra来构建它的CLI,各种参数通过POSIX风格的参数传给APIServer,比如下面的参数示例:
1
2
3
4"--bind-address=0.0.0.0",
"--secure-port=6444",
"--tls-cert-file=/var/run/kubernetes/serving-kube-apiserver.crt",
"--tls-private-key-file=/var/run/kubernetes/serving-kube-apiserver.key",这些显示指定的参数,以及没有指定,而使用默认值的参数,最终都被解析,然后集成到了一个叫做
ServerRunOptions的结构体中,而这个结构体又包含了很多xxxOptions的结构体,比如EtcdOptions,SecureServingOptions等,供后面使用。随后就到了CreateServerChain阶段,这个是整个APIServer启动过程中,最重要的也是最复杂的阶段了,整个APIServer的核心功能就包含在这个里面,这里面最主要的其实干了两件事:一个是构建起各个API对象的Handler处理函数,即针对REST的每一个资源的增删查改方法的注册,比如
/pod,对应的会有CREATE/DELETE/GET/LIST/UPDATE/WATCH等Handler去处理,这些处理方法其实主要是对数据库的操作;第二个就是通过Chain的方式,或者叫Delegation的方式,实现了APIServer的扩展机制,如上图所示,KubeAPIServer是主APIServer,这里面包含了Kubernetes的所有内置的核心API对象,APIExtensions其实就是我们常说的CRD扩展,这里面包含了所有自定义的CRD,而Aggretgator则是另外一种高级扩展机制,可以扩展外部的APIServer,三者通过Aggregator–>KubeAPIServer–>APIExtensions这样的方式顺序串联起来,当API对象在Aggregator中找不到时,会去KubeAPIServer中找,再找不到则会去APIExtensions中找,这就是所谓的delegation,通过这样的方式,实现了APIServer的扩展功能。此外,还有认证,授权,Admission等都在这个阶段实现。然后是PrepareRun阶段,这个阶段主要是注册一些健康检查的API,比如Healthz, Livez, Readyz等;
最后就到了Run阶段,经过前面的步骤,已经生成了让Server Run起来的所有东西,其中最重要的就是Handler了,然后将其通过NonBlocking的方式run起来,即将http.Server在一个goroutine中运行起来;随后启动PostStartHook,PostStartHook是在CreateServerChain阶段注册的hook函数,用来周期性执行一些任务,每一个Hook起在一个单独的goroutine中;这之后就是通过channel的方式将关闭API Server的方法阻塞住,当channel收到os.Interrup或者syscall.SIGTERM signal时,就会将APIServer关闭。
以上,就是对Kubernetes APIServer机制的一个大概认识,了解下APIServer的本质,以及它启动的一个大致流程,后续会对其中一些步骤进行深入剖析。
Kubernetes APIServer 机制概述
https://hackerain.me/2020/08/09/kubernetes/kube-apiserver-overview.html