记录一次Ceph故障—数据平衡之殇
存储是一个公司IT基础设施的重中之重,是最基础的组件,它的稳定保障着上层业务的平稳运行,也保障着很多人的幸福生活,尤其是运维的。
Ceph作为一个流行的开源分布式存储系统,逐渐进入到很多公司的数据中心,它的一个非常重要的特性就是数据动态平衡。大部分存储系统在数据写入后端存储设备后,很少再进行数据迁移,随着时间的推移,设备的不断上架下架,数据会逐渐变的不均衡。Ceph将数据打散,以Object的方式组织数据,然后通过CRUSH算法,计算数据的落位,数据在新旧设备替换时,在设备之间自动进行迁移,比较好的解决了数据不均衡的问题。
经常用到的数据平衡相关的参数主要就是设备的权重值了,即weight和reweight,前者是和磁盘容量大小有直接关系的权重值,一般1T的盘对应的设置的权重值大小为1,该值会参与到CRUSH算法中,去选取OSD,当选择出来OSD之后,还需要使用reweight进行一次过载测试,如果测试失败,则将拒绝该OSD,该值是一个[0,1]之间的数字,默认为1,即不进行过载测试,直接选中该OSD,如果为0,则直接拒绝该OSD,如果居中的话,则会根据哈希的结果,有一定的概率性是否选中该OSD。
本次故障,就是和这两个参数调整相关,因为客户将权重值设置不合理,引发了一系列问题,我觉得该问题挺经典的,也很少在生产中会遇到这个问题,所以有必要记录一下。
首先来看下故障截图吧:
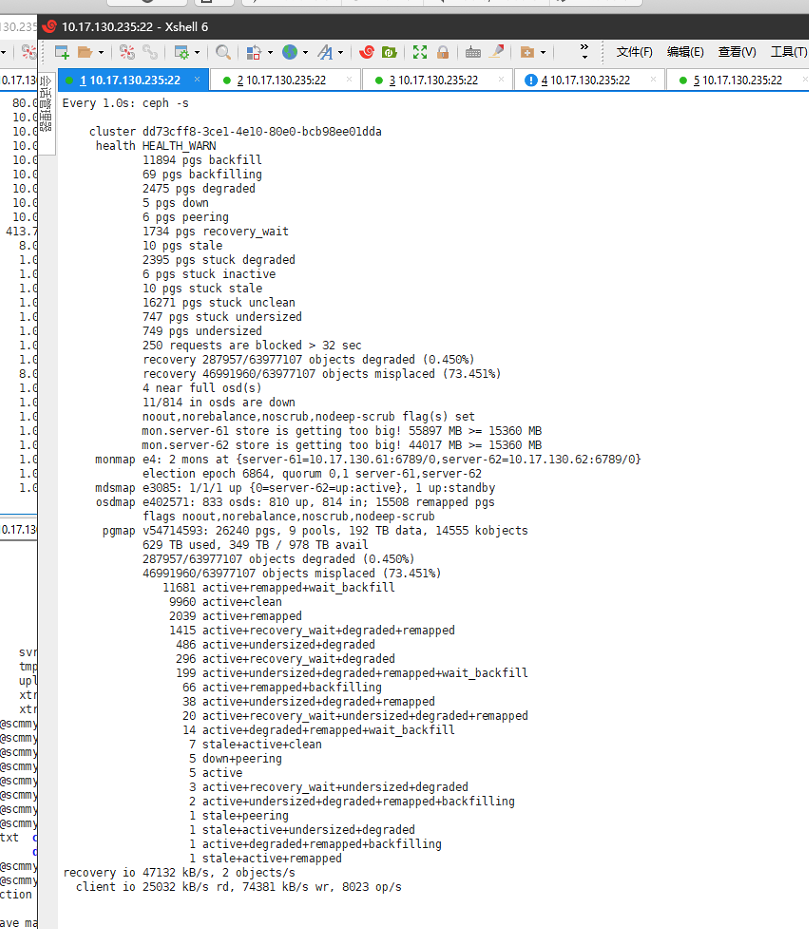
集群中还有大量的快满的OSD:
懂行的同学,可能已经看出来,这个Ceph集群是真的已经故障了,而且还比较严重,具体来说有以下几点:
- 有部分pg处于stale以及inactive的状态,不能对外提供服务,所以有一部分业务IO卡住,其中包括客户的一些核心业务
- 有很多near full的osd,客户将full的值调到了99.5%,当前有大量osd都处于98%的状态
- mon集群状态不正常,首先是63没有在集群中,客户说很早就down掉了,一直加不进去,其次是61和62都报store is too big,而且都有40G多的大小
- 数据分布不均衡,权重值比较混乱,客户在上周末的时候,因为看到集群快满,就扩了4台节点进去,为了尽快让其迁移数据,将上面1.6T的盘的权重值调成了10,并且有的osd,为了尽快迁出使用率高的盘的数据,将其权重设置的非常小,只有0.1,而且有的osd调的weight,有的调的是reweight,而且大部分调的是reweight值。
虽然现在的Ceph状态很危险,但是并没有完全故障,只是影响了一部分业务,部分业务还在正常运行,而且还跑着几个核心系统,不能停,客户非常着急,希望尽快帮忙恢复业务,同时,业务部门已经在着手将数据迁移出来。
经过一番商量,我们决定采用下面的方案进行恢复:
1. 首先要解决mon的问题
因为mon store现在有40G的数据,导致mon的响应非常慢,mon如果不正常的话,会影响后续的操作,而且因为63长期不在quorum中,并且当前集群处在一个非常不健康的状态,有大量的pg在backfill/recovery的状态,会导致mon store的数据增长很快,63基本上是加不进来的,因为63启动的时候需要去leader那里同步数据,同步数据的速度慢于数据增长的速度,导致数据同步不完,无法启动。目前唯一的解决办法就是停掉61和62,进行离线压缩的方法,因为离线压缩速度很快:
1 | ceph-monstore-tool /var/lib/ceph/mon/ceph-server-61 compact |
使用该命令需要安装ceph-test包,因为数据量很大,为了防止互相同步数据,我们将mon同时停掉,然后进行压缩,再启动。关于压缩mon的数据,参考这里的文档:
- https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/3/html/troubleshooting_guide/troubleshooting-monitors#compacting-the-monitor-store
- https://access.redhat.com/solutions/1982273
mon状态的正常非常关键,这里store too big,超过了40G,除了命令执行慢之外,还可能会导致osd down,甚至重启osd卡在booting的阶段。因为集群处在不健康的状态,mon store的数据量增长很快,所以当观察到增长到一定程度的话,就需要再次压缩,直到集群状态恢复正常,mon store的增长速度也恢复正常。
关于停止所有的mon对业务的影响是,对已经跟osd建立连接的客户端其IO是不受影响的,即现有虚拟机的业务不受影响,但是集群不能接受新的IO连接,比如新建卷,重启虚拟机,卸载盘等操作,风险就是当这个时候有osd down的话,那么也会影响该osd上的客户端。
2. 新建replica-domain,迁移数据到新的replica-domain里
客户的故障域模式是这样的:
1 | failure-domain sa01 |
客户受影响的failure-domain里,只有一个replica-domain,叫sa01,这一个replica-domain下的3个osd-domain下,分别有200个左右的osd,故障域非常的大。周末扩容的节点分别加到了这3个osd-domain下,其上已经同步了一小部分数据,原有的osd,有部分使用率达到了98%,20个左右的osd使用率在90%以上。
因此第二步就是要处理高使用率的osd,以防其写满,造成整个集群的故障,因为其原有replica-domain的权重值非常混乱,所以我们将新扩容的节点单独划成一个replica-domain,迁移一部分osd到新的replica-domain上,将其reweight值都设置回1,weight值设置为正常水平,然后让其开始同步数据。设置为新的replica-domain之后的故障域是这样的:
1 | failure-domain sa01 |
注意,尽量保证三个osd-domain的权重值是一致的,否则可能会出现pg选不出来osd的情况。该步骤中的最关键点,是如何确保98%的osd不会继续增长,因此需要给每一个OSD设置一个backfill full的值,将其设置为90%:
1 | ceph tell osd.* injectargs --osd_backfill_full_ratio=0.9 |
该参数的作用是在osd的full比例超过该值时,该osd将会拒绝接受backfill,也即其上的数据不会再接受新平衡数据的迁入,由于客户参数设置错误,将该值设置为了0.995,即99.5%,导致osd的使用率一直涨到了98%,部分涨到99%的osd,被out了出去。设置了该值之后,再平衡数据,将不会往超过90%使用率的osd上迁入数据,保证了其安全性。
3. 处理故障的pg
从ceph的状态中,可以看到,有一部分的pg处于stale/down/peering等状态,这部分异常的pg不能提供对外提供服务,影响了业务的可用性,通过ceph health detail找到这部分异常的pg,发现其中有一些pg的upset中都没有映射到osd,或者三副本只选出来2个osd,没有选出来第3个osd,下面是当时故障的pg的状态:
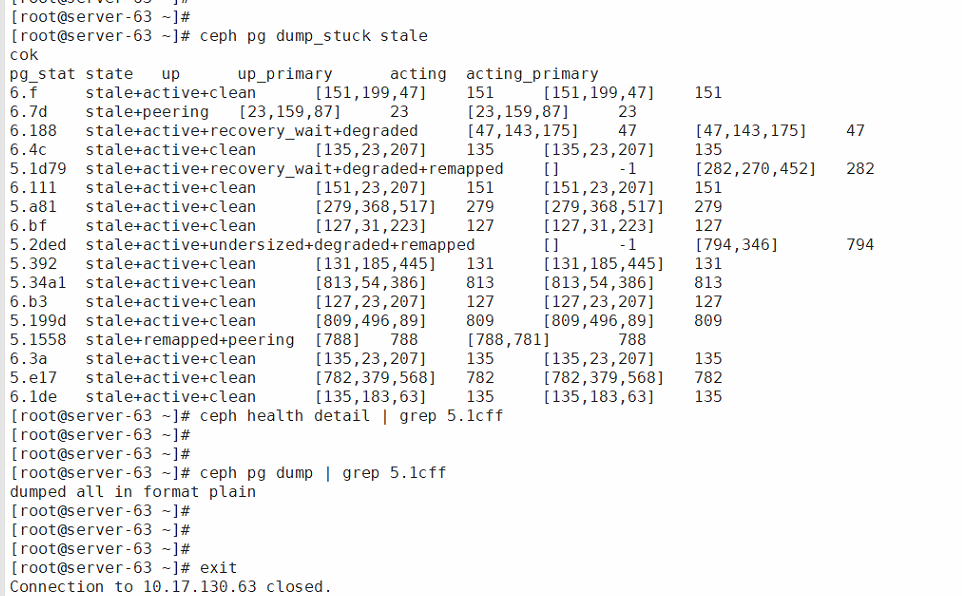
这个现象很有可能是权重不平衡导致的,关于权重在0.94.7版本的ceph中,有两个参数,一个是weight,一个是reweight,weight会参与crush算法,计算出要落位osd,然后reweight是在此基础上再去决定是否选择此osd,但是reweight不会参与crush算法,crush算法本质上是一个概率算法,因此当权重相差悬殊的时候,很有可能选不出来osd,客户环境中部分osd的reweight设置成了0.09,有将近一半的osd都将reweight设置成了小于1的值,这就有可能导致pg出现异常,从而选不出osd。因此尝试将故障pg对应的osd的reweight重置为1:
1 | ceph health detail | grep stale |
置为1之后,观察到该pg重新映射出了osd,并且消除了stale状态,恢复了服务。因为reweight的不确定性,我们调整权重,一般不调整reweight,让它始终保持为1,在L版之前的ceph中,需要通过调整weight值进行数据平衡,L版之后新增了weight-set功能,可以更有效的去平衡数据。
此时,可以将所有reweight不为1的osd重置为1:
1 | for i in `cat reweight_osds.txt`; do setsid ceph osd reweight $i 1; done |
重置为1之后,stale的pg全部恢复了正常,业务也恢复了正常。
4. 数据重平衡
后续需要做的操作就是继续平衡数据,但是要保持各个osd-domain的权重值大小一致,然后可以微调osd的weight值,将一个osd-domain中高使用率的调低,同时也要将另一个osd-domain中低使用率的调高,平衡数据,直到各个osd的使用率趋于均衡。
5. 恢复mon服务
等待数据平衡完成之后,压缩61 62的mon服务,然后启动,再将63加进集群。
至此故障处理完成,所以最终总结一下,引起该故障的本质原因,在于调整数据均衡的方式不对,权重调整的幅度过于大,不同osd之间的权重相差悬殊,导致pg出现了问题,进而引发了后续的一系列问题。因此,关于权重值需要关注以下几点:
- 保持各个bucket的故障域的权重是相等的,bucket里面的osd权重值可以不一致,但是osd上的权重值得保持相等,扩容/缩容,都需要考虑这个问题
- weight不要设置过大与过小,需要跟它的实际容量保持一致
- 尽量不调整reweight值,即使调整,也是微调
记录一次Ceph故障—数据平衡之殇