Kubernetes Kubelet 机制概述
距离上一篇文章,已经过去了将近9个月的时间,2021年第一篇文章,竟然是到8月份了,真没想到这个kubelet竟然拖了我这么长时间。研究api以及scheduler的日夜还历历在目,不知不觉就过了这么长时间,现在突然写起来,恍如隔世的感觉,这一方面说明kubelet相比其他组件确实要更复杂一些,另一方面说明最近这一段时间我有些懈怠了,感觉有50%的时间在忙其他事情,25%的时间在研究kubelet,然后25%的时间在懈怠。不过还好,经过这么长时间断断续续的研究,记了很多笔记,梳理清楚了其大致脉络,对kubelet有了一个比较全面的认知,尤其是跟框架有关的,比如CRI,CNI,CSI等各种Plugin机制,知道了这些框架的原理,不论是做插件开发还是运维,都能够按图索骥,快速找到问题所在,然后再深入到具体的细节中。
其实Kubernetes跟OpenStack在资源管理这个层面上非常类似,都需要涉及到最基础的计算、网络、存储以及各种外设这些资源的管理,在计算上,OpenStack是各种虚拟机,而Kubernetes是各种容器,而这两种计算形态的不同,从本质上决定了OpenStack和Kubernetes的不同,由于容器的易封装、轻量级的特点,逐渐演化出了云原生、微服务等新形式的业务形态,而虚拟机主要还是面向传统的业务形态,OpenStack中的Nova项目通过插件机制可以支持各种虚拟化方案,比如Qemu/KVM, Xen, HyperV, 甚至还有VMWare,当然最常用的还是KVM虚拟化方案,而Kubernetes则通过CRI协议对接各种容器方案,比如最常用的docker, cri-o,还有rkt, kata container等等;至于网络,Kubernetes本身并没有实现什么具体的网络方案,而是仅仅要求Pod之间网络是可以连通的,因此Kubernetes就依赖于第三方提供的网络方案,而第三方的网络方案通过CNI协议跟Container Runtime进行交互,这其实跟OpenStack也很类似,OpenStack的Neutron项目就抽象了二层三层的网络概念供虚拟机使用,而具体的实现则依赖于底层的SDN方案,通常一个成熟的SDN方案,既有面向IaaS的,也有面向PaaS的,他们都有对应的协议标准,所以可以在某一个网络方案上同时对这两者提供服务;至于存储,更是如此,一般存储都以三种形式体现:块存储,文件存储,以及对象存储,每一种形式的存储都有很多协议去实现,比如块存储就有FC、ISCSI、RBD等协议,文件存储有NFS、CephFS等,对象存储则主要是是S3或者是Swift,有的存储系统会同时提供这三种形式的存储,有的则专门只提供一种存储,OpenStack通过Cinder, Manila等项目对接多种存储后端提供不同的存储类型,而Kubernetes则依赖于CSI协议跟第三方存储进行交互。来看看Kubernetes通过各种接口协议跟外部资源整合的图:
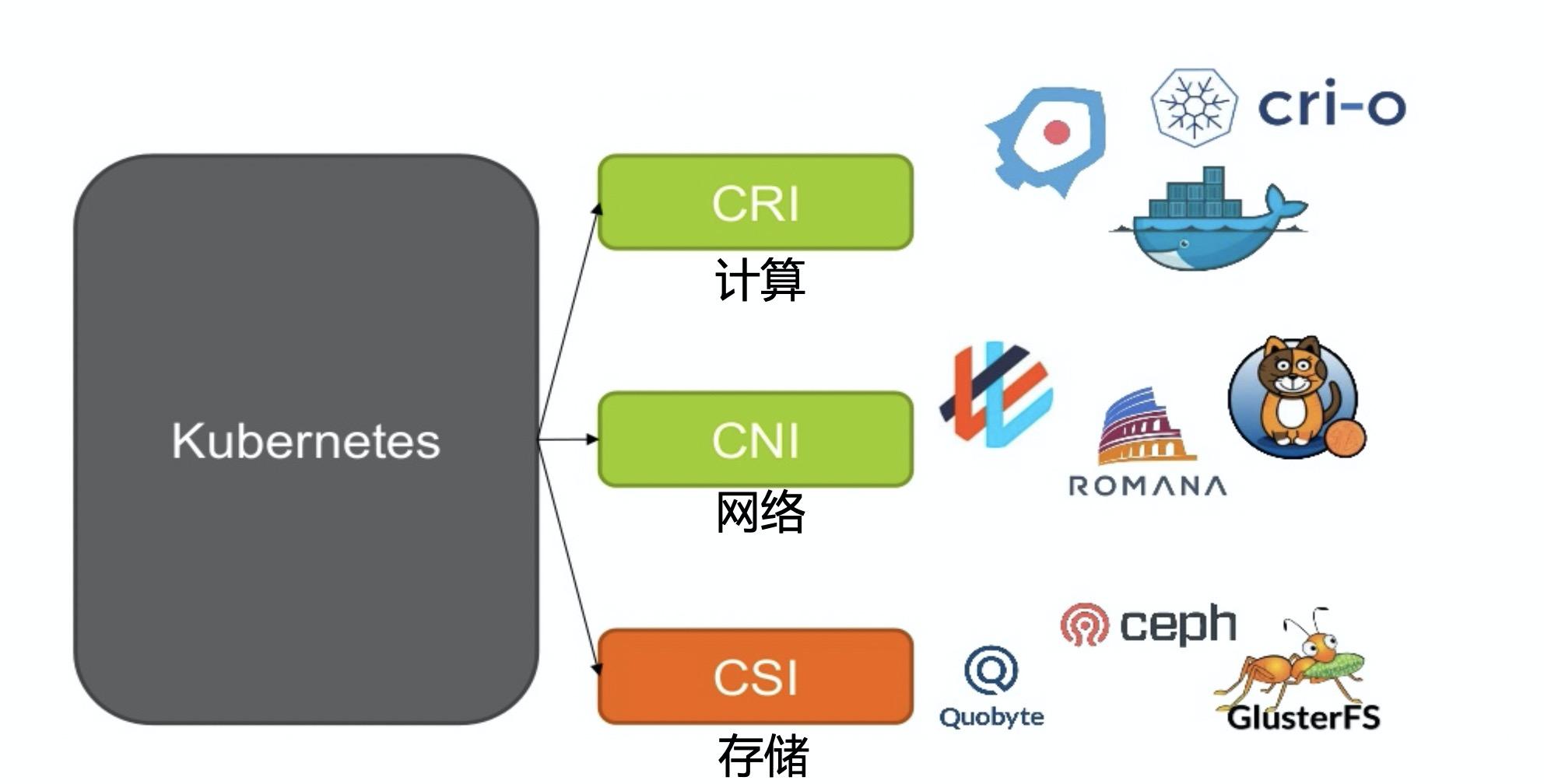
所以从资源管理的角度来说,Kubernetes和OpenStack是存在某些功能上的重叠的,存在一定的竞争关系,Kubernetes完全可以在没有IaaS的环境下使用,直接部署在物理机上,但是两者的定位不同,Kubernetes更偏向于应用侧,侧重于怎么使用资源,而OpenStack等IaaS平台则更侧重于对底层各种硬件资源的统一管理,这在资源隔离上差别很明显,Kubernetes在网络和计算隔离上明显不如OpenStack等IaaS平台彻底,所以更通常的做法是将Kubernetes部署在IaaS平台上,甚至是跨多个云平台部署,充分利用IaaS平台的隔离性和弹性,这样Kubernetes作为IaaS平台的资源消费者而存在,不用去管底层硬件的复杂性和多样性,并且将IaaS平台的使用者由多变的人切换到固定的程序,这对IaaS平台来说会更具确定性和稳定性,所以这两者应该是合作共生的关系,而不是取代的关系,各自在各自的领域里做自己擅长的事情。
Kubernetes对各种资源的使用,则主要依赖于抽象出来的三种接口协议,即CRI, CNI和CSI,在Kubernetes经典的Controller-Loop模型中,kubelet是最终的动作执行者,它部署在每个worker节点,负责当前节点Pod相关的资源生命周期管理,通过这三个接口协议跟远端的资源服务提供者进行交互。通过CRI,向远端的计算资源提供者(容器运行时,Container Runtime)申请对应的容器资源,但是在创建容器之前,先要准备容器所在网络环境,即SandBox,所谓SandBox,其实就是网络命名空间,比如是一个network namespace或者是一个虚拟机,以及在其中的网络设备和相关的网络信息,而这些网络信息则是容器运行时(Container Runtime)通过CNI接口向远端的网络资源提供者申请的,包括IP地址,路由以及DNS等信息,将这些信息配置到网络命名空间中,SandBox就准备好了,然后就可以在其中创建容器了,在同一个SandBox中可以创建多个容器,它们共享同一个网络命名空间,这些就组成了所谓的Pod;Kubelet再通过CSI接口,向远端的存储资源提供者申请对应的存储资源,根据存储类型,可能需要挂载或者格式化成文件系统供Pod使用;这里面有点特殊的就是CNI,kubelet没有直接通过CNI跟网络资源提供者交互,而是由Container Runtime来做这件事,kubelet只需要通过CRI向Container Runtime发送请求,即可获得相关的网络信息。他们之间的关系如下图:

CRI和CSI这两者都是使用gRPC进行的远程过程调用,gRPC是一个高性能、开源、通用的RPC框架,由Google推出,基于HTTP2协议标准设计开发,默认采用Protocol Buffers数据序列化协议,支持多种开发语言,在gRPC客户端可以直接调用不同服务器上的远程程序,使用姿势看起来就像调用本地程序一样,很容易去构建分布式应用和服务。CRI和CSI都对应的提供了一些lib库,在这些库中定义好了客户端和服务端的接口,并且实现了客户端的相关代码逻辑,以及服务端的部分逻辑,作为客户端在使用CRI和CSI时,可以直接引用这些库,向对应的服务资源提供者发送rpc请求,作为服务端,可以引用这些库,更标准和快速的实现服务端的相关逻辑。至于CNI,它就不是通过gRPC的方式了,而是由很多二进制可执行文件组成的网络插件,被Container Runtime调用执行,每个网络插件对应的实现相关的网络功能,CNI也有对应的lib库,针对它的协议,封装了一些公共代码,可以用来方便构建自己的网络插件。
Kubelet实现对Pod以及各种外部资源的管理,主要依赖两个机制:一个是SyncLoop,一个是各种各样的Manager。在SyncLoop中,kubelet会从几个特定的事件来源处,获取到关于Pod的事件,比如通过informer机制从apiserver处获取到的Pod的增删改事件,这些事件触发kubelet根据Pod的期望状态对本节点的Pod做出相应操作,比如新建一个Pod,或者给Pod添加一个新的存储等等,除了apiserver的事件,还有每隔1秒获取到的定期执行sync的事件,周期性的sync事件确保Pod的实际状态跟期望状态是一致的,在Kubelet的实现中,每一个Pod都对应的建了一个worker线程,在该线程中处理对该Pod的更新操作,同一个Pod不能并发进行更新,但是不同Pod是可以并发进行操作的;而各种各样的Manager则负责各种对象以及资源的管理,它们互相配合,形成一个有机的整体,是kubelet各种功能的实现者,比如secretManager/configMapManager等,它们负责从apiserver处通过reflector机制将本节点Pod绑定的secret和configmap缓存到本地,containerManager负责管理container所需要使用到的资源,比如qos, cpu, memory, device等,statusManager负责Pod状态的持续维护,会周期性的将缓存中的pod status通过apiserver更新到数据库中,volumePluginManager负责管理内置(intree)和动态发现的(flexvolume dynamic)的存储插件,csi就是作为intree的一个plugin的形式存在的,volumeManager则是负责管理本节点上的pod/volume/node的attach和mount操作的,等等这些Manager就好比人体的各种器官一样,每个器官负责一个或多个功能,各种器官协调组成一个健康的个体。整体上看,kubelet的架构图如下:

SyncLoop负责Pod的增删改等操作,通过不断轮询,维护Pod这个主体跟期望状态一致,而各种Manager其实是一个个小的Loop,实现了跟Pod相关的某方面的功能,比如维护Pod在本地的缓存,以及Pod的状态的维护,Pod使用计算资源的维护,Pod使用存储资源的维护等等,这些相互配合,共同完成了kubelet完整的功能,所以,未来可能随着需求的变化,会不断有新的Manager被引入,旧的Manager被淘汰,但是总体的架构方式应该不会发生什么太大的变化。
下面梳理了下当前master分支,也就是1.21版本,SyncLoop的大致脉络,以及kubelet中各种Manager的作用简介:
SyncLoop脉络
1 | NewKubeletCommand() |
各种Manager
1 | * cloudResourceSyncManager |
Kubernetes Kubelet 机制概述
https://hackerain.me/2021/08/15/kubernetes/kube-kubelet-overview.html