TCP长连接中断导致的业务问题
本周处理了客户的一个运维Case,是关于TCP长连接的问题,经过两天的排查,最终找到了问题的原因,觉得这个问题挺经典的,所以记录下来。
在接手这个case之前,已经让运维工程师查了几天了,有了一些进展,但是我没有怎么过问,后来客户那边的运维老大打过来电话,特意说了这个事情,并且担忧的说到:“怎么上云有这么多问题,这以后怎么让我们放心?” 我意识到这个问题的严重性,之前这位客户就跟我聊天说过,他们的业务很关键,都是一些重量级的企业客户,得罪不起,上到云上都有哪些坑?有哪些地方需要注意的?我们还需要做哪些改进?
我能理解客户的心情,即使告诉他我们已经有很多客户成功的上云,并且稳定运行很多年了,这些客户中也不乏大规模重量级的业务,但是他仍然没有信心,毕竟他们的业务跟别人不一样,毕竟他们现在看到有很多问题。我知道这不是三言两语就能让他放心的,不是说给他们部署了一个云平台,然后这个生意就算做完了,相反的是这才是万里长征的第一步,后面还有很多的事情和挑战,架构的优化调整,数据的容灾备份,业务的适配上云等等,对自己数据中心的变革绝不仅仅是找个厂商部署个云平台就算万事大吉了,而我们对自己的定位也绝不止步于此。
问题背景
客户有一个Tomcat的应用从原来的物理机上迁移到云平台上,这个应用要通过http去请求一个服务器上的一个应用,这个服务器目前仍然在原来的物理环境里,物理环境和云平台通过三层将网络打通,原来都在物理环境里运行的没有问题,但是将Tomcat应用迁移到云平台之后,发现Tomcat应用到物理环境服务器的http连接无法正常返回,等很久之后连接就异常终止了。Tomcat应用是运行在Windows Server 2008里的,服务端是运行在一台Linux系统中的,还有个特殊点是这个http请求是个重量级的请求,一个请求发过去,正常情况下也要执行几分钟,甚至半小时才能正常返回。
问题分析
因为该http请求可以直接在浏览器上发起,所以在Windows Server自带的IE 8浏览器进行测试,发现浏览器发起请求之后,差不多要等半个小时的时间请求才会失败,为了想看下该请求发起和返回的状态,使用Chrome浏览器进行了相同测试,发现Chrome浏览器竟然能够正常返回,而且只花了几分钟的时间,经过多次测试发现结果都是一样的,这两个浏览器发起的请求有什么区别呢?为什么一个正常,一个却不正常呢?
为了弄清楚底层到底发生了什么,我们对服务端和客户端的网卡进行抓包分析,发现在请求发出去之后,即TCP连接建立起来之后,Chrome会周期性的发送ACK心跳包,服务端抓包情况,如下图:
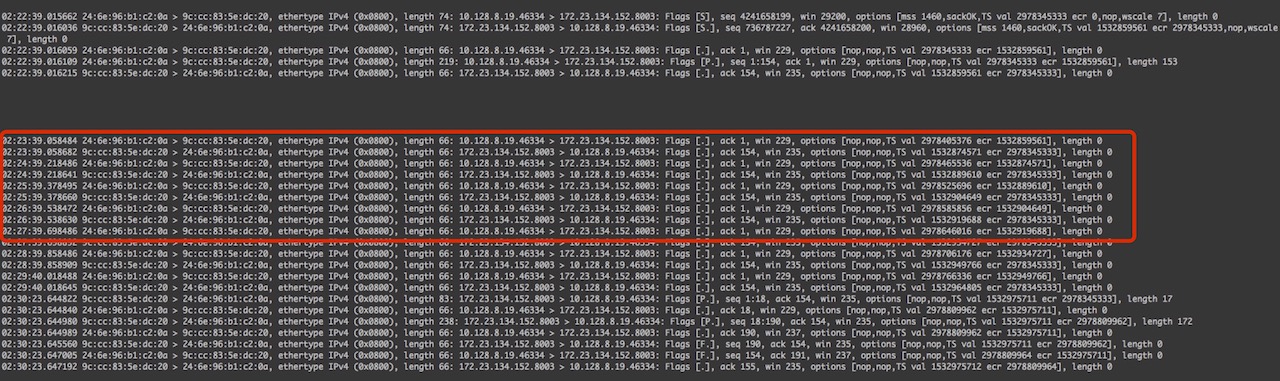
该心跳包是客户端用来保活该TCP连接的,防止TCP连接长时间处于空闲状态,导致被异常断开。当服务端处理完请求,发起断开TCP连接时,整个过程是可以正常断开的。然而IE浏览器发起的请求的行为却不是这样的,下图为IE浏览器测试情况下,在服务端抓包的情况:
可以看到在TCP经过3次握手建立起来连接之后,一直到服务端处理完请求,发起断开连接的Fin包之前,一直没有心跳包,服务端发起的断开连接请求,客户端一直没有回应,但是此时服务端实际上已经处理完了请求,并且主动去断开连接。